Análise Estatística de Dados
Para investigação e estudos de mercado
Meta-Análise: O que é e para que serve?

Autor: Mário Rocha
Introdução
As meta-análises são uma das mais importantes metodologias para resumir de forma quantitativa evidências científicas disponíveis de diversos estudos.
Para Borenstein et al. (2009) esta consiste na combinação estatística dos resultados de múltiplos estudos independentes que procuram dar resposta a uma mesma questão de investigação, possibilitando a obtenção de estimativas mais precisas do que aquelas produzidas unicamente por estudos isolados.
Posteriormente um outro autor (Al-Namaeh, 2025) afirmou que a meta-análise é uma ferramenta fundamental para a tomada de decisão baseada na evidência, especialmente em àreas como as ciências da saúde e outras áreas com um elevado volume de investigação publicada.
Qual é, então, o o verdadeiro objectivo de uma meta-análise?
Principal Objectivo de uma Meta-Análise
Toda a meta-análise tem como principal objectivo resumir de modo quantitativo os resultados de vários estudos, recorrendo a medidas de tamanho de efeito que permitam comparar e combinar os resultados obtidos em diferentes investigações (Borenstein et al., 2009).
E neste sentido qual é a sua importância?
Importância das Meta-Análises
Uma das principais vantagens desta metodologia é a possibilidade de aumentar o poder estatístico através da combinação de múltiplas amostras, o que faz com que as estimativas obtidas tendam a apresentar uma maior precisão e uma menor influência do erro amostral (Borenstein et al., 2009).
Ao falarmos de meta-análise é importante considerar questões como a heterogeneidade e os viês de publicação. O que é isso ao certo?
Heterogeneidade
É importante não só avaliar a estimativa global do efeito mas também o grau de consistência entre os estudos incluídos. Para o efeito e conforme indicado no Cochrane Handbook, valores de I² entr 50% e 75% sugerem heterogeneidade substancial, enquanto valores superiores a 75% indicam heterogeneidade elevada (Al-Namaeh, 2025).
Viés de Publicação
Bartos et al (2022) mencionam o vies de publicação como algo que constitui uma ameaça a ter muito em conta para a validade das meta-análises. Este ocorre quando estudos com resultados estatisticamente significativos apresentam maior probabilidade de publicação do que estudos com resultados nulos ou não significativos.
Para além de conhecer estas questões mais metodológicas é, também, importante saber como analisar os resultados numa meta-análise, e como tal quais os sofwares mais comumemente utilizados.
Principais Softwares para Meta-análise
São diversos os softwares utilizados para este tipo de análise, destacando-se alguns mais tradicionais como RevMan, Comprehensive Meta-Analysis e R, e alguns mais atuais e bastante intituivo como o JASP e o Jamovi, que permitem realizar meta-análises de forma relativamente acessível. O JASP, por exemplo, destaca-se por ser gratuito, open source e disponibilizar uma interface intuitiva para investigadores sem experiência avançada em programação. Um artigo futuro abordará detalhadamente a realização de meta-análises neste software.
Conclusão
Em suma, as meta-análises definem-se como uma das metodologias mais robustas para resumir evidência científica, ao possibilitar combinar resultados de múltiplos estudos e obter conclusões mais precisas e fundamentadas. Para além de elevararem mais o poder estatístico das análises, também permitem uma melhor compreensão dos fenómenos estudados e apoiam a tomada de decisões baseadas na evidência.
Contudo é importante considerar que a realização e interpretação de uma meta-análise exige conhecimentos metodológicos e estatísticos específicos, como a avaliação da heterogeneidade, do viés de publicação e a escolha dos modelos estatísticos mais adequados.
Se pretende realizar uma meta-análise no âmbito de uma dissertação, tese, artigo científico ou projeto de investigação, a Análise Estatística disponibiliza apoio especializado em todas as fases do processo, desde a definição da metodologia até à interpretação e apresentação dos resultados.
Precisa de apoio em Meta-Análises ou outras técnicas de análise estatística? Entre em contacto connosco e descubra como podemos ajudar o seu projeto de investigação.
Referências Bibliográficas
Al-Namaeh, M. (2025). Meta-analysis: A to Z for healthcare professionals. Cureus, 17(3), e80846. https://doi.org/10.7759/cureus.80846
Bartoš, F., Maier, M., Quintana, D. S., & Wagenmakers, E.-J. (2022). Adjusting for publication bias in JASP and R: Selection models, PET-PEESE, and robust Bayesian meta-analysis. Advances in Methods and Practices in Psychological Science, 5(3). https://doi.org/10.1177/25152459221109259
Borenstein, M., Hedges, L. V., Higgins, J. P. T., & Rothstein, H. R. (2009). Introduction to meta-analysis. John Wiley & Sons.
Inteligência Artificial na Investigação Científica: Utilização Responsável, Limitações e Boas Práticas

Autor: Mário Rocha e Flávia Negrini
Introdução
A Inteligência Artificial (IA) tornou-se uma presença cada vez mais frequente no contexto académico e científico e diversas ferramentas como o ChatGPT, Gemini, Claude, Copilot e Perplexity são atualmente utilizadas por estudantes, investigadores e docentes para apoiar tarefas de pesquisa, organização de informação, redação e análise de dados.
Conforme nos refere a Ca’ Foscari University of Venice (2024) o rápido desenvolvimento dos modelos de linguagem de grande dimensão (Large Language Models – LLMs) veio a modificar de modo significativo a forma como a informação é pesquisada, processada e utilizada em contextos científicos.
Assim, apesar do seu potencial, a utilização destas ferramentas levanta importantes questões metodológicas, éticas e científicas e é importante referir que diversas instituições internacionais, como a Wiley, a ETH Zurich, a Comissão Europeia e várias universidades de referência, têm publicado orientações específicas para promover uma utilização responsável da IA na investigação científica. A suas orientações e recomendações convergem numa ideia central, de que a IA pode apoiar o investigador, mas não pode substituir o pensamento crítico, a supervisão humana nem a responsabilidade científica (Wiley, 2025; European Commission, 2025).
Como tal, não é adequado dizer que a IA já substitui o investigador, mas que deve, antes, ser entendida como uma ferramenta de apoio que pode aumentar a produtividade e facilitar determinadas tarefas, ainda que seja sempre necessário supervisão humana, validação rigorosa da informação produzida e respeito pelos princípios da integridade científica. Para a Wiley (2025), os investigadores devem utilizar a IA como um “assistente de investigação”, sendo, contudo, responsáveis pela exatidão dos conteúdos, das referências bibliográficas, das análises e das conclusões apresentadas.
Mas estando a falar de IA, o que é mesmo isso e como funciona?
O que é a IA Generativa e como funciona?
Os modelos de IA generativa, também conhecidos como Large Language Models (LLMs), são treinados com grandes volumes de texto provenientes de livros, websites, artigos científicos e outras fontes digitais e modo como operam centra-se essencialmente na identificação de padrões estatísticos da linguagem, permitindo gerar respostas que aparentam ser coerentes, contextualizadas e linguisticamente corretas.
Porém, é fundamental salientar que estes sistemas não compreendem verdadeiramente a informação da mesma forma que os seres humanos, sendo o seu objetivo principal prever a sequência mais provável de palavras com base nos dados utilizados durante o treino, sendo que, como consequência, a qualidade da resposta depende dos padrões identificados durante esse processo, não resultando de raciocínio científico autónomo ou de compreensão conceptual genuína (Ca’ Foscari University of Venice, 2024).
É esta característica que nos permite compreender como os sistemas de IA conseguem produzir textos aparentemente credíveis, mas também cometer diversos erros factuais, interpretações incorretas ou referências inexistentes. É neste âmbito que a ETH Zurich (2025) já alertou para o facto de estes sistemas não saberem nem pensarem no sentido humano do termo, produzindo antes respostas probabilísticas, o que pode originar fenómenos conhecidos como alucinações, nos quais informação falsa é apresentada como verdadeira. Por esse motivo, qualquer informação produzida por ferramentas de IA deve ser considerada um ponto de partida para análise e nunca uma fonte científica primária.
E então em que a IA pode apoiar a Investigação Ciêntifica?
Como pode a IA apoiar a investigação científica?
A IA pode ser útil em diferentes fases do processo científico, contribuindo para aumentar a eficiência e reduzir o tempo necessário para determinadas tarefas operacionais. São diversas as suas aplicações como:
- Pesquisa bibliográfica e identificação de palavras-chave;
- Organização de conceitos e elaboração de mapas temáticos;
- Resumo preliminar de artigos científicos;
- Apoio à redação e revisão linguística;
- Tradução académica;
- Apoio à programação em R, Python, SPSS Syntax ou outras linguagens;
- Explicação de procedimentos estatísticos e metodológicos;
- Apoio à construção de questionários e guiões de entrevista;
- Organização de dados qualitativos e quantitativos.
Segundo a Ca’ Foscari University of Venice (2024) a IA pode ter bastante utilidade em tarefas repetitivas, demoradas ou de reduzida complexidade intelectual, o que possibilita ao investigadores dedicar-se mais às atividades que exigem pensamento crítico, criatividade e tomada de decisão científica.
Conforme referiu a Wiley (2025) a IA pode apoiar processos como revisões preliminares da literatura, organização de ideias, formatação de referências e revisão linguística de manuscritos. Porém reforçam o facto de estas ferramentas deverem ser utilizadas como complemento ao trabalho do investigador e não como substituto da análise científica.
Apesar de facilitar o processo é muito importante que as fontes originais sejam consultadas e verificadas pelo investigador. A utilização acrítica de resumos produzidos por IA pode conduzir à interpretação incorreta dos resultados de estudos científicos ou à propagação de informação imprecisa.
Neste caso, será que podemos dizer que a IA já substitui totalmente a revisão da literatura por parte dos próprios investigadores?
A IA substitui a pesquisa e revisão da literatura?
Não totalmente.
A IA já consegue apoiar na síntese de artigos científicos e na identificação de literatura potencialmente relevante, através de diversas ferramentas como Perplexity, Elicit, Consensus e Research Rabbit que têm vindo a ganhar popularidade devido à sua capacidade para acelerar as fases iniciais da pesquisa bibliográfica.
Porém é bom esclarecer que uma correcta revisão da literatura é muito mais do que um simples resumo de artigos, implicando também análise crítica, comparação de resultados, identificação de lacunas de investigação, avaliação da qualidade metodológica dos estudos e integração de evidência científica proveniente de múltiplas fontes.
Segundo as orientações da Ca’ Foscari University of Venice (2024), a IA pode ser utilizada para apoiar a identificação inicial de literatura ou para fazer resumos preliminares, mas os investigadores não devem citar ou utilizar trabalhos científicos sem proceder à leitura integral das fontes originais. É importante também alertar, igualmente, para o risco de a IA ignorar estudos relevantes, interpretar incorretamente resultados ou produzir referências inexistentes.
A Wiley (2025) recomenda que qualquer informação obtida através de IA seja posteriormente validada através da consulta direta dos artigos científicos originais, sendo da inteira responsabilidade do autor do trabalho a seleção, interpretação e integração da evidência científica. Assim, a IA pode apoiar a revisão da literatura, mas não substitui as competências científicas necessárias para avaliar criticamente a qualidade e a relevância dos estudos incluídos numa investigação.
E no que respeita à componente empírica e prática dos estudos científicos. A IA já substitui a análise estatística por parte do investigador?
A IA substitui a análise estatística?
Consideramos que também não.
Embora a IA consiga sugerir testes estatísticos, interpretar outputs e gerar código para diferentes softwares, a escolha da análise adequada depende do desenho do estudo, dos objetivos da investigação, das características da amostra e dos pressupostos estatísticos aplicáveis, o que implica conhecimento mais técnico e já alguma experiência.
Apesar de várias ferramentas de IA como ChatGPT, Claude e Copilot conseguirem fornecer explicações detalhadas sobre técnicas estatísticas, auxiliar na programação em R ou Python e até sugerir procedimentos de análise as suas recomendações nem sempre são adequadas ao contexto específico do estudo e podem conter erros metodológicos significativos.
Deste modo, a responsabilidade pela definição metodológica continua a pertencer ao investigador, uma vez que a escolha incorreta de um teste estatístico, a violação de pressupostos ou a interpretação inadequada dos resultados podem comprometer toda a investigação e conduzir a conclusões inválidas.
Sobre este assunto pode consultar outro artigo nosso intitulado:
As orientações internacionais sobre utilização responsável da IA sublinham que a supervisão humana é indispensável em tarefas que envolvem tomada de decisão científica, interpretação de resultados e elaboração de conclusões (European Commission, 2025; Wiley, 2025).
Em resumo, a IA até pode facilitar a aprendizagem de métodos estatísticos e apoiar a execução de análises, mas não substitui totalmente o conhecimento especializado necessário para garantir a validade científica dos resultados obtidos.
Assim, quais são as suas principais limitações e riscos?
Principais limitações e riscos
Entre os principais riscos associados à utilização da IA na investigação científica destacam-se:
- Alucinações, isto é, informação falsa apresentada como verdadeira;
- Referências bibliográficas inexistentes;
- DOI incorretos;
- Enviesamentos presentes nos dados de treino;
- Falta de transparência sobre a origem da informação;
- Dependência excessiva da tecnologia;
- Redução do pensamento crítico quando utilizada de forma inadequada;
- Possível exposição de dados pessoais, confidenciais ou ainda não publicados.
Assim, um dos problemas debatidos com bastante frequência na literatura recente é a possibilidade de os sistemas de IA generativa produzirem respostas plausíveis, mas incorretas. Sobre esta questão, a ETH Zurich (2025) alerta que estas ferramentas não “sabem” nem “pensam” criticamente, mas conseguem produzir conteúdos com base em probabilidades, o que podem levar a que misturem factos com ficção, criem referências inexistentes, apresentem ligações incorretas ou formulem afirmações que parecem cientificamente válidas, mas que não resistem a uma verificação rigorosa.
A Ca’ Foscari University of Venice (2024) também sublinha que os modelos de IA podem dar origem a documentos sintaticamente corretos, mas metodologicamente frágeis, contendo informação falsa, enviesada, incompleta ou difícil de identificar, o que se torna um risco particularmente relevante na investigação científica, uma vez que uma referência inventada, uma interpretação estatística incorreta ou uma conclusão mal fundamentada pode comprometer a credibilidade de todo o trabalho.
Outro risco relevante prende-se com os enviesamentos presentes nos dados de treino, dado que como os modelos de IA são treinados com grandes volumes de informação disponível online, podem reproduzir desigualdades, estereótipos, perspetivas dominantes ou lacunas existentes na própria produção científica. Hagendorff (2020), ao analisar várias orientações internacionais sobre ética da IA, demonstrou que princípios como transparência, justiça, responsabilidade, privacidade e não discriminação são frequentemente mencionados, mas nem sempre são fáceis de aplicar na prática, o que significa que a existência de diretrizes éticas não garante, por si só, uma utilização responsável da tecnologia.
Também a dependência excessiva da IA representa igualmente um risco importante. Llerena-Izquierdo e Ayala-Carabajo (2025) referem que a integração da IA em contextos académicos pode constituir oportunidades significativas, como a otimização da investigação e a personalização da aprendizagem, mas também riscos humanos e éticos, incluindo perda de pensamento crítico, dependência tecnológica e homogeneização de ideias. Assim, quando o investigador passa a aceitar respostas geradas pela IA sem questionar, perde-se uma parte essencial do processo científico, que é a dúvida, a análise crítica e a capacidade de construir conhecimento de forma autónoma.
É neste sentido que a importância da validação humana se tornou particularmente evidente em casos recentes de retratação de artigos científicos associados à utilização inadequada de ferramentas de IA. Como exemplo mais recente temos um artigo, deste mesmo ano, submetido à revista IJC Heart & Vasculature (mais info) que foi retratado após os seus revisores terem identificado múltiplas referências com títulos, autores, revistas e DOI incompatíveis, bem como várias referências que simplesmente não existiam. No aviso de retratação, os editores referiram explicitamente que não conseguiram identificar durante o processo de revisão o uso indevido de ferramentas de IA na elaboração do manuscrito. Este caso demonstra que, embora a IA possa facilitar a redação e a organização da informação, a responsabilidade pela verificação das referências, da qualidade das fontes e da exatidão do conteúdo continua a pertencer integralmente aos autores.
É por este motivo que toda a informação produzida por IA deve ser cuidadosamente verificada, sendo que A IA apesar de poder acelerar tarefas, organizar informação e sugerir caminhos de análise não deve ser utilizada como fonte final de verdade científica e a validação das fontes, a leitura dos documentos originais, a confirmação dos DOI, a análise dos métodos e a interpretação dos resultados continuam a ser responsabilidades humanas.
Questões éticas e integridade científica
As principais orientações internacionais sobre a utilização da Inteligência Artificial na investigação científica convergem em quatro princípios fundamentais: transparência, responsabilidade, supervisão humana e proteção da privacidade (European Commission, 2025; Wiley, 2025; Ca’ Foscari University of Venice, 2024). Como tal voltamos a referir, que embora a IA possa apoiar diversas etapas do processo científico, a responsabilidade pelas decisões metodológicas, interpretações e conclusões permanece sempre do lado do investigador.
A transparência constitui outro elemento central da integridade científica, o que faz com que as orientações da Ca’ Foscari University of Venice (2024) sejam no sentido de os investigadores descreverem claramente de que forma utilizaram ferramentas de IA, especificando, sempre que relevante, os sistemas utilizados, as versões empregues e o papel desempenhado pela tecnologia no desenvolvimento da investigação. Esta transparência é fundamental para garantir a reprodutibilidade científica e permitir que outros investigadores compreendam adequadamente os procedimentos adotados.
Outra preocupação crescente e muito relevante é a proteção da privacidade e da confidencialidade, e neste aspecto a ETH Zurich (2025) alerta para o facto de muitos sistemas de IA armazenarem ou utilizarem os dados introduzidos pelos utilizadores para fins de melhoria dos modelos. Consequentemente, os investigadores devem evitar inserir informações confidenciais, dados pessoais identificáveis, resultados ainda não publicados, informação protegida por acordos de confidencialidade ou conteúdos sujeitos a propriedade intelectual sem as devidas salvaguardas.
Estes preocupações éticas tornam-se particularmente relevantes em áreas que envolvem dados sensíveis ou participantes humanos, e a Wiley (2025) reforça esta questão ao recomendar que os investigadores avaliem cuidadosamente os riscos associados à utilização de IA em projetos que envolvam dados pessoais, informações clínicas, entrevistas, imagens identificáveis ou qualquer conteúdo cuja divulgação possa comprometer a privacidade dos participantes. Em alguns contextos, poderá mesmo ser necessário obter pareceres adicionais das comissões de ética ou rever os consentimentos informados inicialmente obtidos.
Outro aspeto frequentemente discutido refere-se à autoria científica, existindo, na atualidade, um consenso alargado entre universidades, editoras científicas e organismos internacionais de que as ferramentas de IA não podem ser consideradas autoras de artigos científicos. A ETH Zurich (2025) menciona mesmo que os sistemas de IA não podem assumir responsabilidade intelectual pelo conteúdo produzido, não participam conscientemente no processo científico e não podem responder por eventuais erros ou violações éticas, não cumprindo como tal os critérios normalmente exigidos para atribuição de autoria académica.
Além disso, Hagendorff (2020) chamou a atenção para uma questão frequentemente ignorada nos debates sobre IA, que é o facto de a existência de princípios éticos não garantir automaticamente comportamentos éticos. Embora muitas organizações e empresas adotam diretrizes sobre transparência, justiça ou responsabilidade a aplicação prática desses princípios continua a ser um desafio. Assim, a utilização responsável da IA depende não apenas da tecnologia, mas também da formação, do julgamento crítico e do compromisso ético dos próprios investigadores.
Em resumo a integridade científica continua a assentar nos mesmos princípios que orientam a investigação tradicional que são o rigor metodológico, a honestidade intelectual, a transparência, a responsabilidade e o respeito pelos participantes e pela comunidade científica e a IA pode apoiar estes objetivos quando utilizada de forma adequada, embora também possa, igualmente, criar novos riscos quando utilizada sem supervisão ou validação crítica.
E relativamente a outra questão que tantas dores de cabeça tem dado a investigadores e estudantes universitários. Os famosos detectores de IA funcionam realmente?
Detetores de IA: funcionam realmente?
Com o elevado e constante crescimento da utilização de ferramentas de IA generativa também foram surgindo paralelamente diversos sistemas de deteção automática, como Turnitin AI, GPTZero, Copyleaks e ZeroGPT, plataformas que procuram identificar padrões linguísticos que permitam distinguir textos produzidos por humanos de conteúdos gerados por Inteligência Artificial. Contudo, é importante ressalvar que a evidência científica mais recente sugere que a eficácia destes sistemas continua a apresentar limitações significativas.
Num estudo muito recente (Giray et al., 2026) foi analisado o desempenho de vários detetores de IA, tendo-se concluido que a precisão dos resultados varia consideravelmente entre plataformas. Os autores verificaram que alguns sistemas apresentam taxas elevadas de falsos positivos, classificando incorretamente textos produzidos por humanos como conteúdos gerados por IA. Simultaneamente, também foram observados falsos negativos, nos quais textos produzidos por ferramentas de IA não foram identificados corretamente. Tais resultados demonstram que a deteção automática continua longe de oferecer níveis de fiabilidade suficientes para servir como prova definitiva de autoria. Os autores também fazem referência à facilidade com que determinados conteúdos podem escapar à deteção, uma vez que pequenas alterações realizadas pelo utilizador, como reformulações, reorganização de frases ou introdução de exemplos próprios, podem alterar significativamente a classificação atribuída pelos sistemas, sendo também de destacar o facto de que à medida que os modelos de linguagem evoluem e produzem textos cada vez mais semelhantes à escrita humana, os desafios enfrentados pelos detetores tornam-se ainda maiores.
Para além das limitações técnicas, Deep et al. (2025) alertaram para importantes implicações éticas associadas à utilização destes mecanismos em contextos académicos, afirmando que muitos detetores funcionam como sistemas pouco transparentes, não permitindo compreender claramente os critérios utilizados para classificar um texto como humano ou artificial, falta de transparência esta que levanta grandes preocupações relativamente à justiça, à responsabilidade institucional e ao direito dos utilizadores contestarem decisões potencialmente incorretas.
Os problemas tornam-se particularmente relevantes para estudantes multilíngues ou não nativos de inglês e neste caso para Deep et al. (2025), algumas características linguísticas frequentemente presentes nestes grupos podem ser interpretadas pelos algoritmos como indícios de escrita produzida por IA, aumentando o risco de classificações incorretas. Como consequência, determinados estudantes podem ser injustamente penalizados, mesmo quando produziram os seus trabalhos de forma autónoma.
Em suma, tanto Giray et al. (2026) como Deep et al. (2025) defendem que os resultados produzidos pelos detetores de IA não devem ser utilizados como prova única em processos disciplinares ou decisões relacionadas com integridade académica, devendo, antes pelo contrário, ser encarados como indicadores complementares que necessitam sempre de validação humana, análise contextual e avaliação crítica por parte dos docentes ou investigadores envolvidos.
A tendência mais recente nas instituições de ensino superior aponta para uma mudança de paradigma. Em vez de depender exclusivamente da deteção automática, muitas universidades estão a privilegiar estratégias centradas na literacia digital, na utilização ética da IA e na reformulação dos métodos de avaliação, sendo o principal objetivo passa promover uma utilização responsável destas tecnologias, reconhecendo simultaneamente os benefícios que podem trazer para a aprendizagem e para a investigação científica.
É possivel então concluir que os detetores de IA podem constituir uma ferramenta útil de apoio à integridade académica, mas não são infalíveis, uma vez que a evidência científica disponível sugere que devem ser utilizados com prudência, complementados por avaliação humana e enquadrados por políticas institucionais transparentes e justas. Deste modo o maior desafio não é apenas identificar a utilização da IA, mas sobretudo promover uma cultura de responsabilidade, ética e utilização crítica destas tecnologias no contexto académico e científico.
E como podemos referir a utilização de IA?
Como referenciar a utilização de IA?
A crecente utilização de ferramentas de IA generativa na investigação científica levou universidades, editoras e organizações internacionais a desenvolver orientações específicas para garantir transparência e integridade académica e apesar de não existir ainda uma norma universal aplicável a todas as áreas científicas, existe um consenso crescente de que a utilização da IA deve ser declarada sempre que tenha contribuído de forma relevante para a elaboração do trabalho (Wiley, 2025; ETH Zurich, 2025; Ca’ Foscari University of Venice, 2024).
Conforme já foi referido, a transparência é um princípio fundamental da investigação científica e tal como os investigadores descrevem os métodos, os instrumentos utilizados e os procedimentos adotados, também a utilização de ferramentas de IA deve ser comunicada de forma clara quando influencia a redação, organização, análise ou interpretação da informação. Com esta prática leitores, revisores e outros investigadores podem compreender adequadamente o processo de produção científica e avaliar a qualidade do trabalho realizado.
Segundo as orientações da Wiley (2025), a utilização de IA deve ser declarada especialmente quando as ferramentas são utilizadas para produzir texto, reorganizar argumentos, traduzir conteúdos ou apoiar processos metodológicos. A organização recomenda que estas informações sejam incluídas nas secções apropriadas do manuscrito, como os agradecimentos, os métodos ou outras secções destinadas à descrição dos procedimentos utilizados.
A Ca’ Foscari University of Venice (2024) vai ainda mais longe ao recomendar que os investigadores descrevam não apenas a ferramenta utilizada, mas também a sua versão, os objetivos da sua utilização e, sempre que relevante, os prompts ou instruções fornecidas ao sistema, referindo mesmo que é esta transparência que contribui para aumentar a reprodutibilidade da investigação e facilita a avaliação crítica dos resultados obtidos.
Por sua vez, a ETH Zurich (2025) destaca que a utilização não declarada de ferramentas de IA pode constituir uma forma de ocultação da verdadeira origem de determinados conteúdos, defendendo que os autores devem assumir total responsabilidade pelos textos produzidos e indicar claramente quando recorreram a sistemas de IA para apoiar tarefas específicas. Esta necessidade de transparência
A American Psychological Association (APA) também reconhece a necessidade de transparência relativamente à utilização de IA generativa, apontando para o facto de apesar de as ferramentas de IA não serem consideradas autores e não possam ser citadas como fontes científicas convencionais, a sua utilização deve ser descrita quando tiver desempenhado um papel relevante na elaboração do trabalho.
Um exemplo simples de declaração poderá ser:
Foi utilizada uma ferramenta de inteligência artificial para apoio na organização preliminar de ideias, revisão linguística e melhoria da clareza textual. Todo o conteúdo foi posteriormente revisto, validado e adaptado pelo autor.
Contudo em investigações mais complexas, poderá ser necessário fornecer uma descrição mais detalhada, incluindo a ferramenta utilizada, a versão empregue e o tipo de apoio fornecido pela IA.
Importa voltar a reforçar que a utilização de IA não transfere qualquer responsabilidade científica para a tecnologia, sendo que Independentemente do grau de utilização destas ferramentas, os autores continuarem a ser totalmente responsáveis pela exatidão da informação, pela validade metodológica, pela interpretação dos resultados e pelo cumprimento das normas éticas e científicas aplicáveis (Wiley, 2025; ETH Zurich, 2025).
À medida que a utilização da IA se torna mais comum na investigação científica, é expectável que universidades, revistas científicas e entidades financiadoras continuem a atualizar as suas orientações. Por esse motivo, os investigadores devem consultar regularmente as normas específicas aplicáveis à sua instituição, área científica ou publicação de destino, garantindo que a utilização destas tecnologias ocorre de forma transparente, responsável e alinhada com os princípios da integridade científica.
Conclusão
Com a presente revisão e a pesquisa levada a cabo para a sua realização foi possível constatar que a Inteligência Artificial está a transformar profundamente a forma como a investigação científica é desenvolvida, oferecendo novas oportunidades para aumentar a eficiência, facilitar o acesso à informação e apoiar diversas tarefas ao longo do processo de investigação, sendo cada vez mais as ferramentas de IA generativa que podem contribuir para a pesquisa bibliográfica, organização de conteúdos, revisão linguística, programação e apoio metodológico, permitindo que os investigadores reduzam o tempo dedicado a atividades operacionais e concentrem mais esforços na análise e interpretação científica.
Porém apesar destas vantagens, a sua crescente utilização também levanta desafios importantes, como a produção de informação incorreta, referências inexistentes, enviesamentos, problemas de transparência e riscos associados à privacidade que demonstram que a IA não pode ser utilizada de forma acrítica. Assim as várias orientações internacionais analisadas ao longo deste artigo (Wiley, 2025; ETH Zurich, 2025; Ca’ Foscari University of Venice, 2024) são consistentes ao afirmar que a supervisão humana continua a ser indispensável e que a responsabilidade científica permanece sempre do lado dos investigadores .
É então evidente que atualmente a IA deva ser encarada como uma ferramenta de apoio e não como substituto do pensamento crítico, da capacidade analítica ou do julgamento científico que a qualidade da investigação continua a depender da formulação adequada das questões de investigação, da escolha dos métodos, da interpretação rigorosa dos resultados e da capacidade de produzir conhecimento novo e relevante para a comunidade científica.
Para além disso, as questões relacionadas com a ética, a transparência e a integridade científica são de importância crescente e cada mais significativa, uma vez que a utilização responsável da IA implica verificar cuidadosamente toda a informação produzida, proteger dados sensíveis, declarar adequadamente a utilização destas ferramentas e garantir que as decisões científicas permanecem sob controlo humano. Como já salientaram Hagendorff (2020) e a Comissão Europeia (2025), o verdadeiro desafio não se restringe unicamente ao desenvolvimento da tecnologia, mas também à capacidade de assegurar que a sua utilização respeita valores fundamentais como a responsabilidade, a justiça, a transparência e a confiança.
À medida que a Inteligência Artificial continua a evoluir, é provável que o seu papel na investigação científica se torne cada vez mais relevante, embora independentemente dos avanços tecnológicos que venham a surgir, o rigor metodológico, a honestidade intelectual e o pensamento crítico continuem a ser os pilares fundamentais da produção científica. A IA pode acelerar processos e apoiar o trabalho dos investigadores, mas não substitui totalmente a experiência, o conhecimento especializado nem a capacidade humana de compreender, interpretar e produzir ciência de qualidade.
É com este pensamento que a nossa equipa trabalha para apoiar e contribuir para a produção de conhecimento e evidências cientificas de relevo.
Precisa de apoio no seu projeto?
Prestamos apoio especializado em revisão da literatura, metodologia científica, definição amostral, validação de instrumentos, análise estatística (SPSS, JASP, Jamovi, R e SmartPLS), interpretação e discussão de resultados e apoio à redação científica.
Então, se necessita de apoio na elaboração da sua dissertação, tese, artigo científico ou projeto de investigação, entre em contacto para obter acompanhamento especializado e adaptado às necessidades específicas do seu estudo.
Pode também consultar mais sobre os nosso serviços em:
Consultoria em Trabalhos académicos
Explicações de Análise Estatística
Referências Bibliográficas
American Psychological Association (APA) (2026). APA Journals policy on generative AI: Additional guidance. https://www.apa.org/pubs/journals/resources/publishing-tips/policy-generative-ai
Ca’ Foscari University of Venice (2024). Guidelines for the Responsible Use of Artificial Intelligence in Research. Computer Services and Telecommunications Area (ASIT) Working Group for ICT Research Support Activities. https://www.unive.it/pag/fileadmin/user_upload/ateneo/norme_regolamenti/regolamenti/servizi-informatici/Linee_Guida_IA_Ricerca_ENG.pdf
Deep, P.D., Edgington,W.D., Ghosh, N., & Rahaman, M.S. Evaluating the Effectiveness and Ethical Implications of AI Detection Tools in Higher Education. Information 2025, 16, 905. https://doi.org/10.3390/info16100905
ETH Zurich (2025). Plagiarism and generative Artificial Intelligence. https://library.ethz.ch/en/scientific-writing/plagiat-und-kuenstliche-intelligenz-ki.html
European Comission (2026). Guidelines on the ethical use of artificial intelligence and data in teaching and learning for Educators. https://doi.org/10.1007/s11023-020-09517-8doi:10.2766/7967834
Giray, L., Roe, J., & Espiritu, J.D. (2026). AI writing detectors are ineffective, unreliable and harmful. English Teaching: Practice & Critique. https://doi.org/10.1007/s11023-020-09517-810.1108/ETPC-07-2025-0155
Hagendorf, T. (2020). The Ethics of AI Ethics: An Evaluation of Guidelines. Minds and Machines. https://doi.org/10.1007/s11023-020-09517-8
Llerena-Izquierdo, J., & Ayala-Carabajo, R. Ethics of the Use of Artificial Intelligence in Academia and Research: The Most Relevant Approaches, Challenges and Topics. Informatics 2025, 12, 111. https://doi.org/10.3390/informatics12040111
Wiley (2025). AI guidelines for researchers: Using AI tools in your research. https://www.wiley.com/en-nl/publish/article/ai-guidelines/
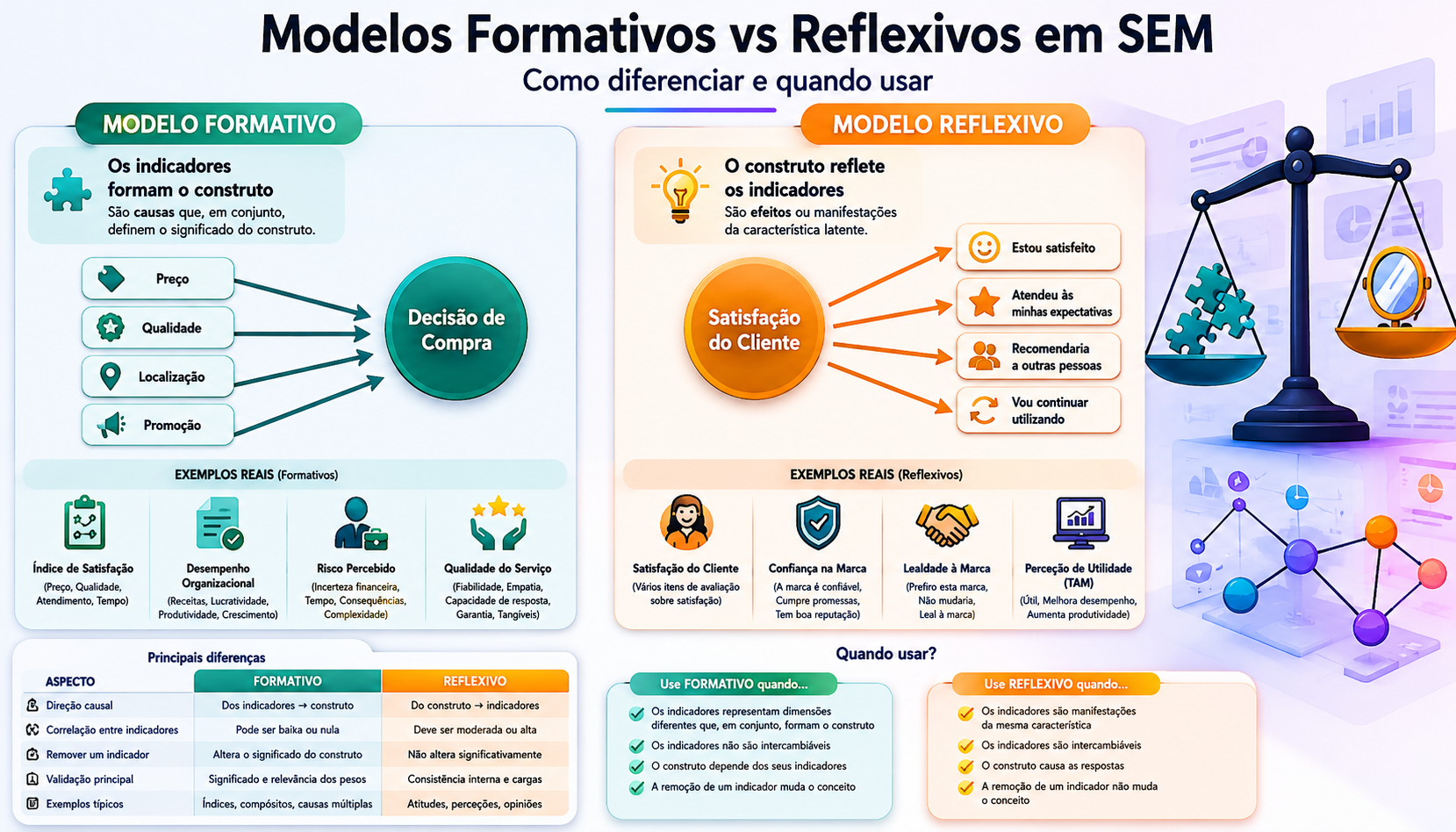
Modelos Formativos vs Reflexivos em SEM: Como diferenciar?
Autor:Mário Rocha
A distinção entre modelos reflexivos e formativos constitui uma das discussões metodológicas mais relevantes na modelagem de equações estruturais (SEM), sendo que apesar do crescimento da utilização de softwares como SmartPLS, AMOS, Mplus e lavaan, ainda são muitas as dificuldades na correta especificação dos construtos.
Jarvis, MacKenzie e Podsakoff (2003), referiram que erros na especificação dos modelos de mensuração podem comprometer significativamente a validade dos resultados e conduzir a interpretações incorretas. Coltman et al. (2008) também reforçam esta ideia ao criticarem a utilização automática de modelos reflexivos em grande parte da literatura de gestão e ciências sociais.
Mais recentemente, autores como Repke et al. (2024), Menold, Bluemke e Hubley (2018) e Hanafiah (2020) apelaram para necessidade de compreender validade, causalidade, dimensionalidade e fundamentação teórica de forma integrada.
Passamos então de seguida a abordar alguns aspectos essenciais para a validade e distinção entre este modelos reflexivos e formativos.
A importância da validade
Menold, Bluemke e Hubley (2018) defendem que a validade representa um dos elementos centrais da medição nas ciências sociais. Os autores referem que a validade não deve ser encarada como uma propriedade fixa de um instrumento, mas sim como um processo contínuo de recolha de evidências. Segundo os autores, muitos estudos concentram-se excessivamente em análises estatísticas internas, negligenciando a validade de conteúdo, processos de respostas, consequências da medição, interpretação conceptual dos resultados. Os autores destacam ainda que os avanços estatísticos e de software facilitaram a obtenção de indicadores estatísticos, mas isso não substitui a necessidade de fundamentação teórica robusta.
Validade e Teoria da Medição
Repke et al. (2024) reforçam que validade deve ser compreendida desde o desenho da investigação até à interpretação final dos resultados. Já Bandalos (2018) apresenta uma abordagem abrangente da teoria da medição nas ciências sociais, destacando a confiabilidade, validade convergente, validade discriminante, equivalência de medição, dimensionalidade e análise fatorial exploratória e confirmatória. Para este autor muitos investigadores utilizam técnicas estatísticas sem compreender adequadamente os pressupostos teóricos subjacentes.
Modelos Reflexivos vs Formativos
Nos modelos reflexivos, o construto latente causa os indicadores observáveis. Assim, alterações no construto tendem a refletir-se nos itens medidos. Segundo Hair et al. (2022) os modelos reflexivos apresentam elevada correlação entre indicadores, consistência interna relevante, intercambialidade entre itens, adequação de Alpha de Cronbach, fiabilidade compósita e AVE. Brown (2015) destacou, ainda, que modelos reflexivos estão fortemente associados à análise fatorial confirmatória (CFA), sendo particularmente comuns em psicologia, educação e marketing.
Nos modelos formativos, os indicadores formam o construto latente. Neste caso, os itens não representam manifestações do construto, mas sim os próprios elementos que o constituem. Diamantopoulos e Winklhofer (2001) defenderam que os construtos formativos exigem uma lógica metodológica diferente, especialmente porque os indicadores podem não apresentar elevada correlação, remover um item altera o significado conceptual e medidas tradicionais de consistência interna podem ser inadequadas. Também Petter, Straub e Rai (2007) reforçaram que construtos multidimensionais em sistemas de informação frequentemente exigem especificação formativa.
Na tabela abaixo apresentamos uma comparação resumo entre modelos formativos e reflexivos
Tabela Comparativa
| Aspeto | Reflexivo | Formativo |
| Direção causal | Construto → indicadores | Indicadores → construto |
| Correlação entre itens | Esperada | Não obrigatória |
| Intercambialidade | Elevada | Baixa |
| Alpha de Cronbach | Importante | Pode ser inadequado |
| AVE | Relevante | Nem sempre apropriada |
| Exemplos | Satisfação, ansiedade | Nível socioeconómico |
| Softwares | AMOS, lavaan | SmartPLS, WarpPLS |
Erros comuns na utilização de modelos formativos e reflexivos
Coltman et al. (2008) desenvolveram uma das discussões metodológicas mais importantes sobre especificação de modelos formativos e reflexivos. Os autores criticaram aquilo que designam como “assunção automática de modelos reflexivos” na literatura. Segundo estes autores, muitos investigadores escolhem modelos reflexivos apenas porque são mais familiares, os softwares facilitam a aplicação e existem mais critérios estatísticos disponíveis. Contudo, os autores alertam que esta prática pode conduzir a problemas graves de validade conceptual e interpretação.
Neste âmbito é fundamental falar de alguns erros comuns.
Entre os erros metodológicos mais frequentes destacam-se a utilização inadequada de Alpha de Cronbach em construtos formativos, a eliminação incorreta de indicadores, a ausência de fundamentação teórica, a utilização automática de modelos reflexivos e a interpretação inadequada de validade convergente e discriminante. Deste modo autores como Jarvis et al. (2003) e Coltman et al. (2008) alertaram que a correta especificação dos construtos deve começar pela teoria e não apenas pelos outputs estatísticos.
Para além desta distinção entre modelos formativos e reflexivos é importante fazer referencia às diferenças entre CB-SEM e PLS-SEM, que também são melhor explicados num outro artigo: “CB-SEM e PLS-SEM: quando usar cada abordagem?”
Referências Bibliográficas
Bandalos, D. L. (2018). Measurement Theory and Applications for the Social Sciences. The Guilford Press.
Brown, T. A. (2015). Confirmatory Factor Analysis for Applied Research (2nd ed.). Guilford Publications
Byrne, B. M. (2016). Structural Equation Modeling with AMOS: Basic Concepts, Applications, and Programming. Taylor & Francis Group
Coltman, T., Devinney, T. M., Midgley, D. F., & Venaik, S. (2008). Formative versus reflective measurement models: Two Applications of Formative Measurement. Journal of Business Research, 61(12), 1250-1262. http://dx.doi.org/10.1016/j.jbusres.2008.01.013
Diamantopoulos, A., & Winklhofer, H.M. (2001). Index Construction with Formative Indicators: An Alternative to Scale Development. Journal of Marketing Research, 38, 269-277. http://dx.doi.org/10.1509/jmkr.38.2.269.18845
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3rd ed.). Sage.
Hanafiah, M. H. (2020). Formative Vs. Reflective Measurement Model: Guidelines for Structural Equation Modeling Research. International Journal of Analysis and Applications. http://dx.doi.org/10.28924/2291-8639-18-2020-876
Jarvis, C. B., MacKenzie, S. B., & Podsakoff, P. M. (2003). A Critical Review of Construct Indicators and Measurement Model Specification in Marketing and Consumer Research. Journal of Consumer Research 30(2), 199-218. http://dx.doi.org/10.1086/376806
Kline, R. B. (2023). Principles and Practice of Structural Equation Modeling (5th ed.). Guilford Press.
Menold, N., Bluemke, M., & Hubley, A. M. (2018). Validity: Challenges in conception, methods, and interpretation in survey research [Editorial]. Methodology: European Journal of Research Methods for the Behavioral and Social Sciences, 14(4), 143–145. https://doi.org/10.1027/1614-2241/a000159
Petter, S., Straub, D., & Rai, A. (2007). Specifying formative constructs in Information Systems Research. MIS Quarterly, 31 (4), 623-656. https://doi.org/10.2307/25148814
Repke, L., Birkenmaier, L., & Lechner, C. M. (2024). Validity in Survey Research – From Research Design to Measurement Instruments. GESIS – Leibniz-Institut für Sozialwissenschaften. https://doi.org/10.15465/gesis-sg_en_048
AMOS vs SmartPLS: Semelhanças, Diferenças, Vantagens e Limitações

Autor: Mário Rocha
A modelagem de equações estruturais (Structural Equation Modeling – SEM) tornou-se uma das metodologias quantitativas mais relevantes nas ciências sociais, gestão, psicologia, educação e saúde. Entre os softwares mais utilizados nesta área destacam-se o AMOS e o SmartPLS, ambos amplamente adotados em investigação científica, embora baseados em abordagens metodológicas distintas.
O AMOS (Analysis of Moment Structures), foi inicialmente criado por Arbuckle e está estritamente associado a uma abordagem covariance-based SEM (CB-SEM) e é muito utilizado em investigação, como forma confirmatória e de validação teórica. Já o SmartPLS é mais popular porque se apresenta simples em termos de funcionamento e tem uma forte associação ao Partial Least Squares SEM (PLS-SEM), particularmente em modelos preditivos e exploratórios, embora em versões mas recentes como a versão 4, já contenha também CBS-SEM.
Independentemente das suas diferenças metodológicas, ambos os softwares desempenham papéis importantes na investigação quantitativa contemporânea e é nesse sentido que este artigo apresenta uma análise comparativa aprofundada entre AMOS e SmartPLS, abordando semelhanças, diferenças, vantagens, limitações, aplicações recomendadas e implicações metodológicas.
O que é o AMOS?
O AMOS é um software desenvolvido para modelagem de equações estruturais baseado em covariâncias (CB-SEM), que se tornou uma das ferramentas mais populares para análise fatorial confirmatória (CFA), validação de modelos teóricos e avaliação de relações causais entre variáveis latentes (Byrne; 2016; Kline, 2023).
Uma das suas principais vantagens é a sua interface gráfica intuitiva, que permite construir modelos através de diagramas visuais, não necessitando de muita programação mais avançada e manual, o que contribuiu significativamente para a popularização do SEM entre investigadores sem experiência avançada em programação.
O AMOS destaca-se particularmente em:
- Validação Confirmatória;
- Testes de ajustamento global do modelo;
- Comparação de modelos teóricos;
- Investigação baseada em teoria consolidada;
- Análises de mediação e moderação.
O que é o SmartPLS?
O SmartPLS é um software focado na abordagem Partial Least Squares Structural Equation Modeling (PLS-SEM). Segundo Hair et al. (2022), o PLS-SEM foca-se mais em objetivos preditivos e exploratórios e é especialmente útil quando os modelos são complexos, as amostras são relativamente pequenas ou os dados não apresentam distribuição normal. Ganhou enorme popularidade em áreas como gestão, marketing, sistemas de informação e empreendedorismo devido à facilidade de utilização e rapidez analítica e destaca-se especialmente em:
- Modelos preditivos;
- Investigação exploratória;
- Modelos complexos;
- Variáveis formativas;
- Análise com pequenas amostras;
- Dados não normais.
Semelhanças e Diferenças entre AMOS e SmartPLS
Apesar de terem diferenças metodológicas, AMOS e SmartPLS apresentam várias semelhanças importantes que passamos as destacar:
- Ambos são softwares de modelagem de equações estruturais;
- Permitem análise de variáveis latentes;
- Utilizam diagramas gráficos intuitivos;
- Possibilitam testes de mediação e moderação;
- São amplamente utilizados em investigação científica;
- Facilitam análise de validade (embora de modo discutível em PLS-SEM) e fiabilidade;
- Suportam modelos complexos com múltiplos construtos.
- Permite análise CB-SEM (O SmartPLS permite a partir da versão 4 (ver Chua, 2024; Hair et al., 2025).
Em resumo, tanto o AMOS quanto o SmartPLS desempenham um papel relevante na investigação quantitativa contemporânea e não devem ser encarados como ferramentas concorrentes absolutas, mas sim como abordagens metodológicas complementares.
Vantagens do AMOS
Apesar do grande crescimento do SmartPls, o AMOS continua as ser muito importante em investigação quantitativa, especialmente quando o objetivo principal é testar modelos teóricos bem fundamentados e também validar escalas de avaliação. Segundo Byrne (2016), uma das grandes forças do AMOS reside na avaliação rigorosa do ajustamento global do modelo e tem como principais vantagens:
- Forte tradição académica;
- Elevada aceitação em revistas científicas;
- Excelente suporte para Análise Fatorial Confirmatória (AFC)
- Indicadores robustos de ajustamento global;
- Integração com SPSS;
- Interface visual intuitiva;
- Adequado para modelos confirmatórios.
Para além disto, é fundamental mencionar que AMOS é muito recomendado para utilização em contextos onde a teoria está bem estabelecida e o objetivo principal é confirmar relações previamente definidas.
Limitações do AMOS
Embora extremamente poderoso, o AMOS apresenta algumas limitações metodológicas e operacionais, como:
- Tende a exigir amostras maiores e maior aproximação à normalidade multivariada.
- Menor flexibilidade para variáveis formativas;
- Maior sensibilidade à não normalidade;
- Limitações em modelos altamente complexos;
- Menor foco preditivo;
- Dependência de pressupostos estatísticos mais rigorosos.
Vantagens do SmartPLS
Segundo Hair et al. (2022), o SmartPLS tornou-se uma das ferramentas mais populares em investigação aplicada devido sua robustez em contextos mais exploratórios e preditivos, e apresenta como principais vantagens:
- Adequado para pequenas amostras;
- Menor exigência de normalidade;
- Excelente desempenho preditivo;
- Facilidade operacional;
- Forte suporte para variáveis formativas;
- Elevada flexibilidade em modelos complexos;
- Rapidez analítica.
Resumidamente, o SmartPLS é particularmente útil quando o objetivo é previsão, desenvolvimento teórico inicial ou investigação exploratória.
Limitações do SmartPLS
Apesar de ter muitas vantagens, o SmartPLS também apresenta limitações importantes, como:
- Menor foco em ajustamento global clássico;
- Maior debate metodológico em alguns contextos;
- Menor adequação para teorias extremamente consolidadas;
- Possibilidade de utilização inadequada sem fundamentação metodológica.
Quando utilizar AMOS?
O AMOS tende a ser mais recomendado quando:
- Existe teoria bem consolidada;
- O objetivo é confirmação teórica;
- Pretende-se testar ajustamento global do modelo;
- As amostras são relativamente grandes;
- Os pressupostos estatísticos são satisfeitos.
Quando utilizar SmartPLS?
O SmartPLS apresenta-se como mais adequado quando:
- O objetivo é previsão;
- A investigação é exploratória;
- Existem variáveis formativas;
- A amostra é relativamente pequena;
- Os dados não apresentam normalidade.
Então qual é o melhor? AMOS ou Smart Pls?
AMOS ou SmartPLS: Qual é Melhor?
A pergunta “qual software é melhor?” pode ser metodologicamente inadequada, uma vez que segundo Hair et al. (2022) e Kline (2023), a escolha entre CB-SEM e PLS-SEM deve depender dos objetivos da investigação e não de preferências pessoais.
Deste modo modo, o AMOS continua extremamente importante em investigação confirmatória e validação teórica rigorosa, enquanto que o SmartPLS se destaca mais pela capacidade preditiva e flexibilidade metodológica.
Assim, ambos os softwares devem ser encarados como ferramentas complementares e não necessariamente concorrentes.
Tabela Comparativa – AMOS vs SmartPLS
| Critério | AMOS | SmartPLS |
| Abordagem | CB-SEM | PLS-SEM |
| Objetivo principal | Confirmação teórica | Predição e exploração |
| Base estatística | Covariâncias | Variância |
| Distribuição normal | Preferencial | Não obrigatória |
| Pequenas amostras | Menos recomendado | Mais adequado |
| Variáveis formativas | Limitado | Muito forte |
| Complexidade operacional | Moderada | Baixa |
| Interface gráfica | Muito intuitiva | Muito intuitiva |
| Indices de Ajustamento global | Muito forte | Mais limitado |
| Predição | Moderada | Muito forte |
| Aceitação histórica | Muito elevada | Crescente |
| Áreas mais comuns | Psicologia, educação, saúde | Gestão, marketing, IS |
| Tipo de investigação | Confirmatória | Exploratória/preditiva |
| Integração com SPSS | Sim | Não direta |
| Curva de aprendizagem | Moderada | Relativamente simples |
Importância da Evolução Recente do SmartPLS
Um aspeto particularmente relevante nos últimos anos é a evolução metodológica do SmartPLS. Estando historicamente associado sobretudo ao PLS-SEM, é importante salientar que as versões mais recentes do software (desde 2024) passaram também a incorporar funcionalidades relacionadas com CB-SEM, o que constitui um desenvolvimento importante na área da modelagem de equações estruturais.
Em termos mais práticas esta evolução aumenta significativamente as possibilidades analíticas do SmartPLS, permitindo maior flexibilidade metodológica aos investigadores, uma vez que deixou de estar exclusivamente ligado a abordagens preditivas e exploratórias, passando também a integrar procedimentos associados à validação confirmatória.
Tal facto contribuiu para aumentar ainda mais a popularidade do SmartPLS em contextos académicos e profissionais, especialmente entre investigadores que procuram combinar análise preditiva, validação teórica e modelos complexos num único software.
Conclusão
Em suma, o AMOS e o SmartPLS representam duas das ferramentas mais relevantes em modelagem de equações estruturais contemporânea. Deste modo, enquanto o AMOS mantém forte tradição em investigação confirmatória baseada em covariâncias, o SmartPLS consolidou-se em investigação exploratória e preditiva.
Então, a escolha adequada destes softwares depende dos objetivos analíticos, da natureza dos dados, da fundamentação teórica e do contexto metodológico da investigação.
Em vez de procurar um “vencedor absoluto”, os investigadores devem compreender as características, potencialidades e limitações de cada abordagem (PLS-SEM e CB-SEM) e respetivos softwares (SPSS Amos e SmartPLS)
Para além dos artigos que temos disponíveis sobre CB-SEM VS PLS-SEM e Importância do CB-SEM para a validação de escalas, também aconselhamos vivamente a ler o nosso artigo sobre modelos formativos vs modelos reflexivos:
Importância do CB-SEM para a Validação de Escalas de Avaliação
CB-SEM e PLS-SEM: Quando usar cada abordagem
Modelos Formativos vs Reflexivos em SEM: Como diferenciar?
Apoio Especializado em AMOS e SmartPLS
A utilização adequada de AMOS e SmartPLS exige não apenas domínio técnico do software, mas também conhecimento metodológico sólido relativamente à modelagem de equações estruturais, sendo que muitas das dificuldades, erros e problemas em dissertações, teses e artigos científicos surgem não pela utilização do software em si, mas por alguns fatores como:
- Escolha inadequada da abordagem metodológica;
- Interpretação incorreta dos outputs;
- Construção inadequada do modelo;
- Avaliação incorreta da validade e fiabilidade;
- Utilização inadequada de mediação e moderação.
Deste modo, disponibilizamos apoio especializado em:
- Modelagem de Equações Estruturais;
- PLS-SEM e CB-SEM;
- Validação de Instrumentos (Análise Fatorial Exploratória e Confirmatória)
- Mediação e Moderação;
- Interpretação de outputs AMOS e SmartPLS;
- Apoio metodológico para teses, dissertações e artigos científicos.
O grande objetivo é auxiliar investigadores e estudantes a desenvolver análises metodologicamente robustas e alinhadas com as melhores práticas científicas contemporâneas.
Referências Bibliográficas
Byrne, B. M. (2016). Structural Equation Modeling with AMOS (3rd ed.). Routledge.
Chua, Y.P. (2024). A step-by-step guide to SMARTPLS 4: Data analysis using PLS-SEM, CB-SEM, Process and Regression. Researchtree. https://www.researchgate.net/publication/379413546_A_step-by step_guide_to_SMARTPLS_4_Data_analysis_using_PLS-SEM_CB-SEM_Process_and_Regression
Hair, J., Babin, B.J., Ringle, C.M., & Sarstedt, M. (2025). Covariance-based structural equation modeling (CB-SEM): a SmartPLS 4 software tutorial. Journal of Marketing Analytics, 13 (3). https://doi.org/10.1057/s41270-025-00414-6
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3rd ed.). Sage.
Kline, R. B. (2023). Principles and Practice of Structural Equation Modeling (5th ed.). Guilford Press.
A Importância do CB-SEM na Validação de Questionários: Um Erro Frequente com a Utilização do PLS-SEM

Autor: Mário Rocha
A crescente popularidade do PLS-SEM
Nos últimos anos, o PLS-SEM tornou-se uma das técnicas mais utilizadas na investigação aplicada., sendo que a sua flexibilidade, facilidade de utilização e menor exigência em termos de tamanho da amostra contribuíram para que seja cada vez mais utilizado em diversas áreas como gestão, marketing, educação, saúde e ciências sociais.
Porém é muito importante ter em conta que a popularidade desta metodologia trouxe também alguns equívocos/erros metodológicos que importa discutir, como o caso da utilização do PLS-SEM para validar questionários ou escalas de avaliação.
Validação de questionários não é apenas fiabilidade
É comum encontrar estudos onde a validação de um instrumento é baseada exclusivamente em indicadores como:
- Consistência interna (Alfa de Cronbach; Fiabilidade composta; Omega)
- Validade convergente;
- Validade discriminante.
Embora estes indicadores sejam importantes, a sua existência não garante, por si só, que um questionário esteja devidamente validado, porque um instrumento pode apresentar excelentes indicadores estatísticos e, ainda assim, possuir problemas ao nível da sua estrutura fatorial. Dai a importância da realização da validade fatorial com recurso a uma técnica como a análise fatorial confirmatória (AFC)
O papel da Análise Fatorial Confirmatória (AFC)
Quando o objetivo é validar um instrumento de medida, uma das questões fundamentais é verificar se os dados suportam a estrutura teórica proposta.
Por exemplo, se um questionário foi desenvolvido para medir três dimensões distintas, é necessário demonstrar que os itens se organizam efetivamente de acordo com essa estrutura, é precisamente neste ponto que entra a análise fatorial confirmatória (AFC), normalmente realizada em contexto CB-SEM.
Ao contrário do PLS-SEM, o CB-SEM permite avaliar diretamente o ajustamento entre o modelo teórico e os dados observados através de índices globais de ajustamento, que fornecem evidência sobre a adequação da estrutura fatorial proposta, como por exemplo:
- CFI
- GFI
- TLI;
- RMSEA;
- SRMR;
- Qui-quadrado de ajustamento (x2/gl)
O verdadeiro papel do PLS-SEM
Importa esclarecer que este artigo não pretende desvalorizar o PLS-SEM. Muito pelo contrário. Importa é fazer um correcta distição entre os dois métodos (PLS-SEM e CB-SEM). Deste modo, o PLS-SEM constitui uma metodologia extremamente útil quando o objetivo é:
- Testar modelos estruturais complexos;
- Maximizar a variância explicada;
- Desenvolver teoria;
- Realizar análises preditivas;
- Estudar relações entre constructos latentes.
O problema surge quando se assume que bons indicadores de fiabilidade e validade (convergene e divergente/discriminante) são suficientes para concluir que um instrumento está validado, sendo que na realidade, estes indicadores avaliam aspetos importantes da qualidade das medidas, mas não substituem a necessidade de confirmar a estrutura fatorial do instrumento.
Um erro metodológico frequente
É muito comum, na prática, muitos investigadores concluirem que um questionário está validado porque apresenta:
- Consistência Interna adequada
- Alfa de Cronbach superior a 0,70;
- Fiabilidade composta superior a 0,70;
- Boa validade Convergente
- AVE superior a 0,50;
- Critérios de validade discriminante adequados
- Entre os critérios mais utilizados encontram-se o critério de Fornell-Larcker, baseado na comparação entre a raiz quadrada da AVE e as correlações entre constructos, a análise das cargas cruzadas (cross loadings) e o rácio Heterotrait-Monotrait (HTMT). Atualmente, o HTMT é frequentemente considerado uma das abordagens mais robustas para avaliar a validade discriminante)
Contudo, estas evidências não demonstram necessariamente que os itens representam corretamente os fatores teóricos definidos pelo investigador, o que em muitos casos, apenas uma AFC permite identificar focada em questões como:
- Cargas fatoriais inadequadas;
- Itens problemáticos;
- Cargas cruzadas.
- Dimensões mal especificadas;
- Problemas de ajustamento global.
Uma abordagem recomendada
Sempre que possível, a validação de questionários deve ser encarada como um processo sequencial. Assim, uma estratégia frequentemente recomendada consiste em:
- Desenvolver ou adaptar o instrumento (com processos de tradução-retradução e validade de contéudo, se necessário)
- Realizar uma Análise Fatorial Exploratória (AFE);
- Confirmar a estrutura fatorial através de AFC em contexto CB-SEM
- Utilizar posteriormente o instrumento em modelos estruturais mais complexos, sendo desta forma, a qualidade da medida é também avaliada antes da análise das relações entre constructos.
Considerações Finais
O PLS-SEM é um método extremamente poderoso e útil para testar modelos estruturais e realizar análises preditivas. Contudo, a validação de questionários exige mais do que apenas a análise de indicadores de consistência interna, validade convergente e validade discriminante.
Entao, a demonstração de que a estrutura teórica proposta é efetivamente suportada pelos dados continua a ser um dos pilares fundamentais da validação de instrumentos.
Confundir a avaliação de métricas do modelo de medida com a validação fatorial de um questionário constitui um dos erros metodológicos mais frequentes na utilização do PLS-SEM, sendo como tal fundamental proceder a análise fatorial confirmatória através do método CB-SEM.
Para mais informações sobre os métodos PLS-SEM e CB-SEM pode também ler o nosso artigo mais especifico:
CB-SEM e PLS-SEM: quando usar cada abordagem?
Precisa de apoio na validação de Escalas de Avaliação?
Se necessita de apoio na construção, adaptação ou validação de instrumentos de medida, bem como na realização de análises fatoriais exploratórias, confirmatórias ou modelos de equações estruturais, entre em contacto. Uma escolha metodológica adequada é fundamental para garantir resultados robustos e cientificamente sustentados.
Pode contactar-nos directamente pelo whatsapp ou através dos contactos no site.
A Importância da Análise de Dados e da Investigação de Mercado nas Organizações Modernas

Autor: Mário Rocha e Flávia Negrini
Introdução
Nas últimas décadas, a quantidade de informação disponível para as organizações aumentou de forma exponencial, o que levou empresas, instituições públicas, organizações sem fins lucrativos e entidades de investigação a recolherem diariamente dados provenientes de clientes, colaboradores, fornecedores, sistemas de gestão, websites, redes sociais e aplicações móveis. Contudo, a simples acumulação de dados não constitui uma vantagem competitiva, sendo que o verdadeiro valor encontra-se na capacidade de transformar essa informação em conhecimento útil para apoiar a tomada de decisão.
Davenport e Patil (2012) referiram que os dados tem um papel fulcral na economia moderna, tornando a análise de informação uma competência estratégica para organizações de diferentes dimensões. De forma semelhante, Kotler e Keller (2016) defendem que a compreensão dos consumidores, mercados e tendências constitui um dos pilares da gestão contemporânea.
Neste contexto, a investigação de mercado, a análise estatística e as abordagens mais recentes de Business Analytics aparecem como ferramentas complementares que permitem reduzir a incerteza, apoiar decisões e identificar oportunidades de melhoria. Embora os métodos e tecnologias tenham evoluído significativamente, os princípios fundamentais como formular as perguntas corretas, recolher dados de qualidade, analisar a informação de forma rigorosa e interpretar os resultados de forma adequada, permanecem inalterados.
Posto isto porque as organizações necessitam de informação para o seu processo de tomada de decisão?
Porque as Organizações Precisam de Informação para Decidir?
Todas as decisões organizacionais envolvem algum grau de incerteza e neste sentido, o lançamento de um novo produto, a definição de uma estratégia comercial, a avaliação da satisfação dos clientes ou a implementação de um programa de formação exigem informação fiável para reduzir o risco associado à decisão.
Historicamente, muitas decisões eram tomadas com base na experiência acumulada dos gestores ou em observações informais do mercado. Embora a experiência continue a desempenhar um papel importante, com a crescente complexidade dos mercados começou a ser fundamental uma abordagem mais estruturada e baseada em evidências.
Neste sentido, a utilização sistemática de dados permite compreender melhor os consumidores, identificar padrões de comportamento, monitorizar indicadores de desempenho e avaliar o impacto de intervenções organizacionais. Então, a informação passa a deixar de ser apenas um recurso operacional e passa a constituir um ativo estratégico.
É neste que já anteriormente Davenport e Harris (2007) referiram que as organizações mais competitivas são frequentemente aquelas que conseguem transformar dados em conhecimento útil e integrar essa informação nos seus processos de decisão.
Considerando estas questões podemos então levantar a questão: Qual será o papel da investigação e estudo de mercado?
O Papel da Investigação de Mercado
A investigação de mercado é frequentemente associada à aplicação de questionários ou à realização de estudos de satisfação. No entanto, o seu alcance é muito mais abrangente.
Conforme ja referiu Malhotra (2019) a investigação de mercado consiste, essencialmente, na identificação, recolha, análise e disseminação sistemática de informação destinada a apoiar a tomada de decisão. De forma semelhante, Churchill e Iacobucci (2010) referiram que o principal objetivo da investigação consiste em produzir conhecimento relevante para compreender problemas e oportunidades organizacionais.
Entre as aplicações mais comuns da investigação de mercado encontram-se:
- Estudos de satisfação dos clientes
- Avaliação da qualidade dos serviços;
- Estudos de notoriedade e imagem de marca;
- Análise da concorrência;
- Segmentação de mercado;
- Avaliação de produtos e serviços;
- Estudos de clima organizacional;
- Avaliação de programas e projetos.
Segundo Sarstedt e Mooi (2019) a investigação de mercado deve ser vista como um processo estruturado que inclui a definição do problema, o desenho da investigação, a recolha dos dados, a análise da informação e a comunicação dos resultados. Então, para além de recolher informação, a investigação procura produzir conhecimento que permita fundamentar decisões e reduzir a incerteza.
Qual é então a importância da qualidade dos dados?
A Importância da Qualidade dos Dados
A qualidade dos resultados obtidos depende diretamente da qualidade dos dados recolhidos e uma das ideias mais importantes da metodologia de investigação é que análises sofisticadas não conseguem compensar problemas associados à recolha inadequada de informação. Então dados incompletos, enviesados ou pouco fiáveis conduzem inevitavelmente a conclusões mais frágeis ou mesmo inadequadas.
Dillman, Smyth e Christian (2014) demonstraram que erros na construção dos instrumentos de recolha podem comprometer significativamente a validade dos resultados, uma vez que questões ambíguas, linguagem inadequada, escalas mal construídas ou sequências pouco lógicas podem introduzir enviesamentos difíceis de corrigir posteriormente.
É neste sentido que a qualidade metodológica deve ser considerada desde as fases iniciais da investigação, sendo que as suas várias fases como a definição clara dos objetivos, a seleção adequada dos participantes e a construção rigorosa dos instrumentos de recolha constituem etapas fundamentais para garantir a utilidade dos resultados obtidos.
Porque são então importantes os questionários para a recolha de informação?
Questionários e Recolha de Informação
Os questionários continuam a ser um dos instrumentos mais utilizados em investigação aplicada e a sua popularidade provém da capacidade de recolher informação de um grande número de participantes de forma relativamente rápida e económica. Porém, a aparente simplicidade dos questionários pode levar à subvalorização da sua complexidade metodológica.
É neste sentido que Malhotra (2019) mencionou que um bom questionário deve ser desenvolvido a partir dos objetivos da investigação e não apenas das informações que o investigador gostaria de obter. Cada questão deve contribuir diretamente para responder ao problema em estudo. Então, entre os aspetos mais relevantes destacam-se:
- Clareza e simplicidade das perguntas;
- Adequação da linguagem ao público-alvo;
- Utilização correta das escalas de resposta;
- Ordem lógica das questões;
- Minimização de enviesamentos;
- Realização de pré-testes.
Em resumo, a qualidade dos dados recolhidos depende, em grande medida, da qualidade do instrumento utilizado.
E no que se refere à amostragem? O que é isso é qual é a sua importância?
A Importância da Amostragem
Na maioria das situações, não é possível recolher informação junto de todos os elementos de uma população. Consequentemente, os investigadores recorrem à utilização de amostras, o que leva a que a amostragem constitua um dos pilares da investigação quantitativa.
Segundo Cochran (1977), uma amostra adequadamente selecionada permite obter estimativas fiáveis sobre uma população mais ampla. Outro anterior Kish (1965), já tinha anteriormente destacado que a representatividade da amostra é um dos fatores mais importantes para garantir a validade das conclusões. Ou seja, uma amostra enviesada pode comprometer todo o estudo, independentemente da qualidade das análises realizadas posteriormente. Neste caso, conforme refereriam Cătoiu, Stanciu e Țichindelean (2011) a inferência estatística apenas é válida quando o processo de amostragem respeita critérios metodológicos rigorosos.
Em suma, na prática, muitos erros de investigação não resultam de problemas estatísticos complexos, mas sim de amostras inadequadas ou mal definidas, e como tal a definição da população-alvo, o método de seleção dos participantes e a determinação da dimensão amostral devem receber atenção especial.
E relativamente ao processo de análise estatística dos dados? O que é mais comum? Tanto a estatistica mais geral e descritiva como os vários tipos de estatistica inferencial direccionada para o teste de hipóteses são fundamentais para um bom processo de tomada de decisão.
Da Estatística Descritiva à Estatística Inferencial
Após a recolha dos dados, torna-se necessário transformar observações em informação útil, é neste ambito que a estatística descritiva constitui frequentemente o primeiro nível de análise. Diversas medidas estatísticas como médias, frequências, percentagens, desvios-padrão, assim como representações gráficas permitem resumir grandes volumes de informação e identificar padrões relevantes. Porém é importante considera que a compreensão dos fenómenos organizacionais exige frequentemente análises mais aprofundadas.
Diversos autores de referência na àrea como Field (2018), Agresti (2018), Levine, Stephan e Szabat (2020) e Montgomery e Runger (2018) demonstram que a estatística inferencial permite generalizar conclusões obtidas numa amostra para uma população mais ampla. Assim, através de testes de hipóteses, intervalos de confiança e por exemplo, modelos de regressão é possível responder a questões como:
- Existem diferenças significativas entre grupos?
- Que fatores influenciam a satisfação dos clientes?
- Qual o impacto de uma intervenção organizacional?
- Que variáveis explicam determinado comportamento?
Em suma, todas estas abordagens permitem transformar dados em evidências que apoiam a tomada de decisão.
E quando se trata de análises mais complexas, como a análise multivariada, o que podemos dizer? E qual a sua relação com fenómenos organizacionais?
Análise Multivariada e Compreensão dos Fenómenos Organizacionais
Os fenómenos organizacionais raramente dependem de uma única variável. Temos como exemplo o fato da satisfação poder ser influenciada pela qualidade do produto, atendimento, preço, confiança e imagem da marca. Da mesma forma, o desempenho dos colaboradores pode depender de fatores relacionados com liderança, motivação, formação e clima organizacional.
Autores de referência em estatística multivariada (Hair et al, 2019, 2022) destacam a importância das técnicas multivariadas para compreender fenómenos complexos e referem igualmente que estas abordagens permitem analisar simultaneamente múltiplas variáveis e identificar relações difíceis de observar através de métodos mais simples. Assim, entre as técnicas mais utilizadas encontram-se:
- Regressão múltipla;
- Análise fatorial;
- Análise de clusters;
- Modelos de equações estruturais.
Estas ferramentas contribuem para uma compreensão mais aprofundada dos fenómenos organizacionais e apoiam decisões mais fundamentadas.
E o que podemos dizer em relação a análise de negócios, mais conhecida por business analytics? O que tem a ver com as investigações de mercado?
Da Investigação de Mercado ao Business Analytics
A investigação de mercado evoluiu significativamente ao longo das últimas décadas. Tradicionalmente, os dados eram obtidos através de questionários, entrevistas e observação. Porém, nos tempos que correm as organizações dispõem também de informação proveniente de sistemas de gestão, plataformas digitais, redes sociais e bases de dados de clientes. Foi esta evolução que deu origem a conceitos como Business Intelligence, Business Analytics e Data Analytics.
Assim, apesar das diferenças terminológicas, o objetivo continua essencialmente o mesmo: utilizar informação para apoiar decisões.
Para Davenport e Harris (2007) as organizações mais competitivas utilizam dados como recurso estratégico. Posteriormente Wedel e Kannan (2016) reforçaram esta questão ao demonstrar que a análise de dados permite compreender melhor os consumidores, personalizar ofertas e melhorar a eficácia das estratégias de marketing.
Assim, o Business Analytics não substitui a investigação tradicional, sendo que a complementa através da integração de novas fontes de informação.
O que dizer sobre o facto de por vezes as organizações recolherem muitos dados mas não produzirem conhecimento com os mesmos?
Porque Muitas Organizações Recolhem Dados Mas Não Produzem Conhecimento?
Um dos paradoxos da atualidade é que muitas organizações recolhem grandes quantidades de informação sem conseguir transformá-la em conhecimento útil, sendo importante salientar que, por vezes, a existência de dashboards, relatórios e indicadores não garante, por si só, melhores decisões. Entre os problemas mais frequentes destacam-se:
- Falta de objetivos claros;
- Indicadores inadequados;
- Dados de baixa qualidade;
- Interpretação incorreta dos resultados;
- Ausência de ligação entre análise e decisão.
É neste sentido que Chen (2022) refere que o valor dos dados depende da capacidade de os transformar em informação acionável. De forma semelhante, Davenport e Harris (2007) sublinham que o verdadeiro desafio não consiste em recolher mais dados, mas em utilizar os dados existentes de forma inteligente.
Quais são assim os principais desafios e limitações que consideramos relevantes na investigação de mercado e na análise estatística de dados neste âmbito?
Desafios e Limitações
Apesar das suas vantagens, a análise de dados apresenta limitações. Assim, entre os desafios mais frequentes encontram-se:
- Dados incompletos;
- Enviesamentos amostrais;
- Problemas de medição;
- Interpretações incorretas;
- Confusão entre correlação e causalidade.
Em conclusão, já como tinha referido Field (2018) é muito importante compreender os pressupostos dos métodos utilizados e evitar conclusões simplistas.
A tecnologia pode facilitar a análise, mas não substitui o rigor metodológico, a interpretação crítica e o conhecimento do contexto organizacional.
Conclusão
A análise de dados e a investigação de mercado desempenham um papel central nas organizações modernas. Desde os estudos tradicionais de satisfação até às abordagens mais recentes de Business Analytics e Big Data, o objetivo permanece essencialmente o mesmo: apoiar decisões através de informação fiável e relevante.
Embora as ferramentas tecnológicas continuem a evoluir rapidamente, os fundamentos da investigação aplicada mantêm-se inalterados. A qualidade dos dados, a adequação da amostragem, o rigor da análise e a interpretação crítica dos resultados continuam a ser fatores determinantes para transformar informação em conhecimento útil.
É assim fundamental, que as organizações que investem numa cultura orientada por dados estejam melhor preparadas para compreender os seus clientes, antecipar tendências e enfrentar os desafios de um ambiente cada vez mais competitivo.
Se a sua organização pretende desenvolver estudos de mercado, avaliar a satisfação de clientes ou colaboradores, analisar dados organizacionais ou obter apoio metodológico e estatístico para projetos específicos, poderá beneficiar de acompanhamento especializado ao longo de todo o processo.
Precisa de Apoio na Recolha, Análise ou Interpretação de Dados?
Referências Bibliográficas
Aaker, D. A., Kumar, V., & Day, G. S. (2007). Marketing Research. John Wiley & Sons.
Agresti, A. (2018). Statistical Methods for the Social Sciences (5th ed.). Pearson.
Cătoiu, I., Stanciu, O., & Țichindelean, M. (2011). Statistical Inference Used in Marketing Research. Studies in Business and Economics, 130–136.
Chen, Y. (2022). Statistics and Big Data in Business Marketing. Advances in Economics, Business and Management Research, 219, 615–618.
Churchill, G. A., & Iacobucci, D. (2010). Marketing Research: Methodological Foundations. Cengage.
Cochran, W. G. (1977). Sampling Techniques (3rd ed.). Wiley.
Davenport, T. H., & Harris, J. G. (2007). Competing on Analytics. Harvard Business School Press.
Davenport, T. H., & Patil, D. J. (2012). Data Scientist: The Sexiest Job of the 21st Century. Harvard Business Review, 90(10), 70–76.
Dillman, D. A., Smyth, J. D., & Christian, L. M. (2014). Internet, Phone, Mail, and Mixed-Mode Surveys. Wiley.
Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). Sage.
Hair, J.F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis (8th ed.). Cengage.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3rd ed.). Sage.
Kish, L. (1965). Survey Sampling. Wiley.
Kotler, P., & Keller, K. L. (2016). Marketing Management (15th ed.). Pearson.
Levine, D. M., Stephan, D. F., & Szabat, K. A. (2020). Statistics for Managers Using Microsoft Excel (9th ed.). Pearson.
Malhotra, N. K. (2019). Marketing Research: An Applied Orientation (7th ed.). Pearson.
Montgomery, D. C., & Runger, G. C. (2018). Applied Statistics and Probability for Engineers (7th ed.). Wiley.
Sarstedt, M., & Mooi, E. (2019). A Concise Guide to Market Research (3rd ed.). Springer.
Wedel, M., & Kannan, P. K. (2016). Marketing Analytics for Data-Rich Environments. Journal of Marketing, 80(6), 97–121.
Análise Categórica e Principais Testes Estatísticos
Autor: Mário Rocha
Introdução
A análise categórica envolve métodos estatísticos utilizados para estudar variáveis qualitativas ou categóricas, como género, estado civil, presença/ausência de doença ou categorias de resposta em questionários. Este tipo de análise é fundamental em áreas como saúde, psicologia, marketing, educação e ciências sociais, permitindo identificar associações, padrões e probabilidades entre categorias (Hazra & Gogtay, 2016).
As variáveis categóricas podem ser nominais (sem ordem) ou ordinais (com ordem lógica), sendo que os dados são normalmente organizados em tabelas de contingência e analisados através de testes estatísticos específicos (Hazra & Gogtay, 2016).
São diversos os testes estatisticos que trabalham com dados categóricos como: 1) Teste Qui-Quadrado e respectivas alternativas, 2) Análise de Correspondéncias Simples (Anacor) e Múltiplas (MCA), 3) Regressão Logística, 4) Decision Trees (Árvores de Decisão).
1. Teste do Qui-Quadrado (χ²)
O teste do Qui-Quadrado é um dos métodos mais utilizados na análise categórica, tendo como principal objetivo verificar se existe associação significativa entre variáveis categóricas (Hazra & Gogtay, 2016). Apresenta diferentes tipos como:
• Qui-quadrado de independência;
• Qui-quadrado de ajustamento (goodness-of-fit);
• Teste de McNemar;
• Teste exato de Fisher.
Este método estabelece a comparação entre frequências observadas com frequências esperadas e tem como principais pressupostos a necessidade dos dados serem categóricos, as observações independentes e as frequências esperadas adequadas (Hazra & Gogtay, 2016).
Em amostras pequenas, o teste exato de Fisher pode representar uma alternativa mais robusta ao Qui‑Quadrado tradicional conforme nos referiram Shan e Gerstenberger (2017). Além disso, Agresti e Caffo (2000) demonstraram melhorias importantes na estimação de intervalos de confiança associados às diferenças entre proporções.
2. ANACOR e MCA
A Análise de Correspondências (ANACOR) permite representar graficamente relações entre categorias de variáveis qualitativas. Por outro lado, a Análise de Correspondências Múltiplas (MCA) é mais utilizada quando existem várias variáveis categóricas simultaneamente. Deste modo, a Análise de Correspondências Simples (ANACOR) é utilizada principalmente para explorar relações entre duas variáveis categóricas, enquanto a Análise de Correspondências Múltiplas (MCA) representa uma extensão da técnica para múltiplas variáveis categóricas simultaneamente (Pestana & Gageiro, 2014; Greenacre, 2017).
Estas técnicas são muito usadas em questionários, segmentação de clientes, marketing e investigação social. As principais vantagens incluem visualização intuitiva das associações, redução dimensional e identificação de perfis e agrupamentos. (Greenacre, 2017; Agresti, 2018).
Tem como principais pressupostos para a sua utilização a necessidade das variáveis a analisar serem categóricas, amostras adequadas e categorias suficientemente representadas. Estas abordagens são especialmente úteis em estudos exploratórios e análise de perfis multivariados (Pestana & Gageiro, 2014; Hair et al.,2019; Agresti, 2018).
3. Regressão Logística
A regressão logística é utilizada para prever probabilidades em variáveis dependentes categóricas. Ao contrário da regressão linear, trabalha com probabilidades entre 0 e 1 através da função logística (Maroco, 2021; Park, 2013; Sperandei, 2014).
Segundo Maroco (2021) os seus principais tipos são:
• Binária (Variável dependente ou de resposta dicotómica)
• Multinomial (Variável dependente ou de resposta nominal com mais de 2 categorias)
• Ordinal (Variável dependente ou de resposta ordinal)
Assim, a regressão logística permite estimar probabilidades, identificar fatores de risco, controlar variáveis de confusão e calcular Odds Ratios (OR), sendo amplamente utilizada na investigação científica e em modelos preditivos (Park, 2013).
Entre os principais pressupostos destacam-se independência das observações, ausência de multicolinearidade severa e tamanho amostral adequado (Sperandei, 2014).
4. Decision Trees (Árvores de Decisão)
As árvores de decisão são métodos de classificação e previsão amplamente utilizados em Data Mining e Machine Learning. O modelo divide sucessivamente os dados em grupos homogéneos através de regras simples (Song & Lu, 2015;Mienye & Jere, 2016).
Algoritmos conhecidos incluem CART, CHAID, C4.5 e QUEST (Kingsford & Salzberg, 2008; Mienye & Jere, 2016 ). Entre as principais vantagens destacam-se a facilidade de interpretação, a capacidade de lidar simultaneamente com variáveis categóricas e contínuas, a identificação automática de interações e a elevada capacidade preditiva (Kingsford & Salzberg, 2008; Song & Lu, 2015). Além disso, estas técnicas apresentam elevada flexibilidade e aplicabilidade em áreas como saúde, marketing, bioinformática, deteção de fraude e previsão de comportamento (Mienye & Jere, 2016).
Porém é importante salientar que estes modelos podem apresentar sensibilidade aos dados e risco de overfitting (Kingsford & Salzberg, 2008; Song & Lu, 2015)), sendo que técnicas de pruning, validação cruzada e ensemble learning são frequentemente utilizadas para melhorar a robustez e generalização dos modelos (Mienye & Jere, 2016)
Conclusão
A análise categórica reúne métodos fundamentais para investigação científica e análise de dados. O Qui‑Quadrado continua a ser uma das abordagens mais utilizadas para estudar associações entre variáveis qualitativas, enquanto técnicas como ANACOR, MCA, regressão logística e árvores de decisão oferecem abordagens mais avançadas de exploração, classificação e previsão.
A escolha do método depende dos objetivos do estudo, tipo de variável e estrutura dos dados, sendo fundamental compreender os pressupostos e limitações de cada abordagem (Hazra & Gogtay, 2016; Park, 2013).
Este artigo serve apenas como uma breve introdução à temática sendo a mesma explorada de modo mais especifico em diferentes futuros artigos.
Referências Bibliográficas
Agresti, A. (2018). Statistical Methods for the Social Sciences (5th ed.). Pearson.
Agresti, A., & Caffo, B. (2000). Simple and effective confidence intervals for proportions and differences of proportions result from adding two successes and two failures. The American Statistician, 54(4), 280–288. https://doi.org/10.1080/00031305.2000.10474560
Hazra, A., & Gogtay, N. (2016). Comparing groups – categorical variables. Indian Journal of Dermatology, 61(4), 385–392. https://doi.org/10.4103/0019-5154.185700
Kingsford, C., & Salzberg, S. L. (2008). What are decision trees? Nature Biotechnology, 26(9), 1011–1013. https://doi.org/10.1038/nbt0908-1011
Park, H.-A. (2013). An introduction to logistic regression: From basic concepts to interpretation. Journal of Korean Academy of Nursing, 43(2), 154–164. https://doi.org/10.4040/jkan.2013.43.2.154
Shan, G., & Gerstenberger, S. (2017). Fisher’s exact approach for post hoc analysis of a chi-squared test. PLOS ONE, 12(12), e0188709. https://doi.org/10.1371/journal.pone.0188709
Song, Y.Y., & Lu, Y. (2015). Decision tree methods: Applications for classification and prediction. Shanghai Archives of Psychiatry, 27(2), 130–135. https://doi.org/10.11919/j.issn.1002-0829.215044
Sperandei, S. (2014). Understanding logistic regression analysis. Biochemia Medica, 24(1), 12–18. https://doi.org/10.11613/BM.2014.003
Fávero, L. P., Belfiore, P., Silva, F. L., & Chan, B. L. (2009). Análise de Dados: Modelagem Multivariada para Tomada de Decisões. Elsevier.
Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). Sage.
Greenacre, M. (2017). Correspondence Analysis in Practice (3rd ed.). Chapman & Hall/CRC.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis (8th ed.). Cengage.
Maroco, J. (2021). Análise Estatística com o SPSS Statistics (8º Edição). Report Number.
Mienye, I. D., & Jere, N. (2016). A Survey of Decision Trees: Concepts, Algorithms, and Applications. IEEE Access. https://doi.org/10.1109/ACCESS.2024.3416838
Pestana, M. H., & Gageiro, J. N. (2014). Análise de Dados para Ciências Sociais: A Complementaridade do SPSS (6.ª Edição). Edições Sílabo.
CB-SEM e PLS-SEM: quando usar cada abordagem?

Autor: Mário Rocha
A Modelagem de Equações Estruturais (SEM) é uma família de técnicas que permite analisar, no mesmo modelo, relações entre variáveis latentes e indicadores observáveis. Na prática, junta a lógica da análise fatorial com a análise de caminhos/regressão, sendo útil quando o investigador quer testar relações complexas por exemplo entre conceitos como satisfação, intenção, desempenho, confiança ou adoção tecnológica. A literatura distingue sobretudo duas abordagens: CB-SEM, baseada em covariâncias, e PLS-SEM, baseada em variância/compósitos (Dash & Paul, 2021; Hair et al., 2017).
O CB-SEM é mais indicado quando a teoria já está bem consolidada e o objetivo principal é confirmar se o modelo teórico se ajusta bem aos dados. A sua lógica é comparar a matriz de covariâncias observada com a matriz estimada pelo modelo, dando grande importância a índices de ajustamento como qui-quadrado (x2/gl), CFI, TLI, RMSEA, GFI e SRMR. Por isso, é uma abordagem forte para validação teórica, análise fatorial confirmatória e modelos reflexivos/fatoriais, mas tende a exigir mais dos dados, nomeadamente amostras adequadas, boa qualidade de medição e, em muitos casos, pressupostos de normalidade (Dash & Paul, 2021; Vargör & Öğretmen, 2025).
O PLS-SEM, por sua vez, é geralmente escolhido quando o objetivo é explicar e prever. Em vez de tentar reproduzir a matriz de covariâncias, procura maximizar a variância explicada dos constructos dependentes. Por isso, tornou-se popular em estudos exploratórios, modelos complexos, desenvolvimento de teoria, investigação aplicada e contextos em que o interesse está mais na capacidade preditiva do que no ajustamento global do modelo (Hair et al., 2022; Henseler et al., 2009; Richter et al., 2020; Ringle et al., 2023; Sarstedt et al., 2020; Changalima & Chuwa, 2025). Hair et al. (2017) sublinham, também, que o PLS-SEM trabalha com a lógica de compósitos e utiliza a variância total, enquanto o CB-SEM trabalha sobretudo com variância comum.
Tabela comparativa entre CB-SEM e PLS-SEM
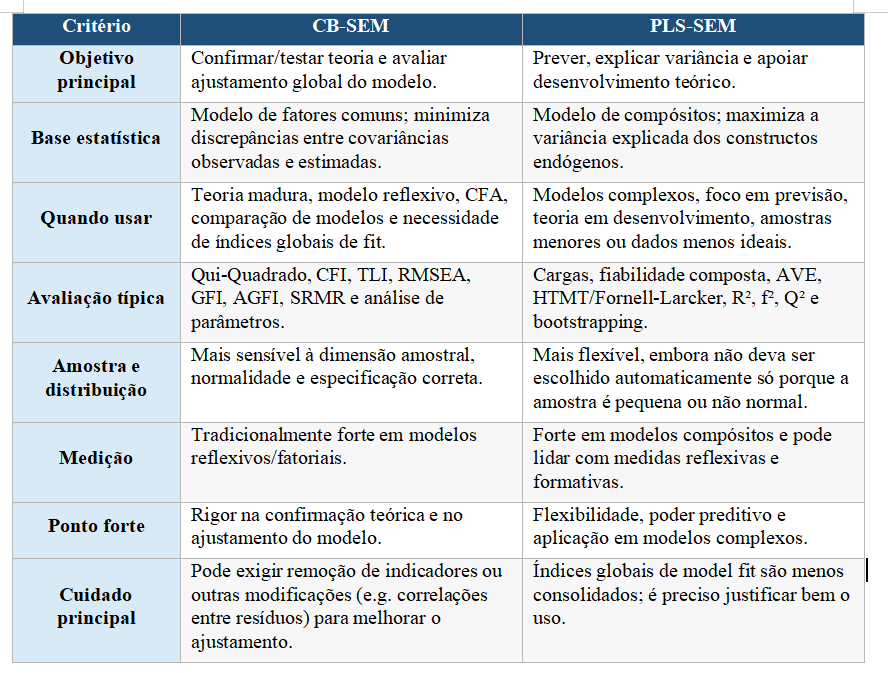
Alguns resultados empíricos reforçam esta distinção. No estudo de Dash e Paul (2021), com 466 respondentes, as cargas dos itens tenderam a ser mais elevadas no PLS-SEM, enquanto o CB-SEM se destacou por oferecer uma avaliação mais completa do ajustamento global. O mesmo estudo mostrou que o PLSc – uma versão consistente do PLS – produz relações estruturais mais próximas do CB-SEM, sobretudo quando o modelo é de natureza fatorial/reflexiva.
Hair et al. (2017) também observaram que o PLS-SEM tende a reter mais indicadores e a apresentar bons níveis de fiabilidade composta e validade convergente, enquanto o CB-SEM pode exigir a eliminação de itens para atingir bom ajustamento. No entanto, estes autores não tratam os métodos como rivais: a escolha depende da pergunta de investigação. Se a prioridade é confirmar uma teoria, o CB-SEM é mais natural; se a prioridade é previsão e explicação prática, o PLS-SEM pode ser mais adequado.
Investigações recentes tornam a discussão ainda mais equilibrada. Vargör e Öğretmen (2025), ao compararem CB-SEM, PLS-SEM e PLSc-SEM em dados do PISA, concluíram que o CB-SEM apresentou melhores índices de ajustamento, enquanto PLS-SEM e PLSc-SEM foram úteis para parâmetros de fiabilidade e validade. Porém, alertam que é incorreto dizer que o PLS-SEM é sempre preferível em amostras pequenas ou distribuições não normais. Também Henseler e Schuberth (2024) acrescentam que tanto CB-SEM como PLSc evoluíram e podem lidar com modelos que incluem fatores comuns e compósitos, desde que o modelo seja especificado corretamente.
Assim, a melhor decisão não é perguntar qual método é melhor, mas qual método serve melhor o objetivo do estudo. Então, a mensagem essencial é simples: CB-SEM é mais forte para confirmação teórica e avaliação rigorosa de modelos fatoriais e estruturais. Já o PLS-SEM é mais forte para previsão, exploração e modelos orientados para variância. Em ambos os casos, a teoria, a qualidade dos dados, o tipo de constructo e a transparência na justificação metodológica continuam a ser mais importantes do que a escolha automática de um software.
Referências Bibliográficas
Changalima, I.A., & Chuwa, M.P. (2025). Partial Least Squares Structural Equation Modeling (PLS-SEM) in business research: A simple guide for novice researchers. International Journal of Research in Business and Social Science, 14(9), 497-506. https://doi.org/10.20525/ijrbs.v14i9.4601
Dash, G., & Paul, J. (2021). CB-SEM vs PLS-SEM methods for research in social sciences and technology forecasting. Technological Forecasting and Social Change, 173. https://doi.org/10.1016/j.techfore.2021.121092
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (3rd ed.). Sage.
Hair Jr., J. F., Matthews, L. M., Matthews, R. L., & Sarstedt, M. (2017). PLS-SEM or CB-SEM: Updated guidelines on which method to use. International Journal of Multivariate Data Analysis, 1(2), 107-123. https://doi.org/10.1504/IJMDA.2017.087624
Henseler, J., & Schuberth, F. (2024). Should PLS become factor-based or should CB-SEM become composite-based? Both! European Journal of Information Systems, 34 (3). https://doi.org/10.1080/0960085X.2024.2357123
Henseler, J., Ringle, C. M., & Sinkovics, R. R. (2009). The use of partial least squares path modeling in international marketing. Advances in International Marketing, 20, 277–319. https://doi.org/10.1108/S1474-7979(2009)0000020014
Richter, N. F., Schubring, S., Hauff, S., Ringle, C. M., & Sarstedt, M. (2020). When Predictors of Outcomes are Necessary: Guidelines for the Combined Use of PLS-SEM and NCA. Industrial Management & Data Systems, 120(12), 2243–2267. https://doi.org/10.1108/IMDS-11-2019-0638
Ringle, C. M., Sarstedt, M., Mitchell, R., & Gudergan, S. P. (2023). Partial Least Squares Structural Equation Modeling in HRM Research. The International Journal of Human Resource Management, 31(12), 1617–1643. https://doi.org/10.1080/09585192.2017.1416655
Sarstedt, M., Hair, J. F., Cheah, J.-H., Becker, J.-M., & Ringle, C. M. (2020). How to Specify, Estimate, and Validate Higher-Order Constructs in PLS-SEM. Australasian Marketing Journal, 27(3), 197–211. https://doi.org/10.1016/j.ausmj.2019.05.003
Vargör, D., & Öğretmen, T. (2025). Comparison of covariance-based structural equation model and partial least squares equality models. General Surgery and Clinical Medicine, 3(2), 1-9. https://doi.org/10.21203/rs.3.rs-4991578/v1
A Importância da Escolha Metodológica na Investigação Científica e a sua Relação com a Análise Estatística

Autores: Mário Rocha e Flávia Negrini
A escolha metodológica representa uma das etapas mais importantes em qualquer investigação científica. Apesar disso, muitos investigadores iniciam os seus estudos focando-se primeiro na análise estatística ou no software a utilizar, negligenciando a definição adequada da metodologia. Porém é fundamental referir que a literatura científica demonstra claramente que a análise estatística deve ser consequência do desenho metodológico e não o ponto de partida.
No presente artigo apresentam-se algumas questões que consideramos de extrema relevância para uma adequada e mais robusta Investigação Científica, como:
1. Metodologia Qualitativa e Quantitativa: Quais as diferenças e quando utilizar
A distinção entre metodologia qualitativa e quantitativa constitui uma das decisões mais relevantes em investigação científica.
Autores relevantes na área como Creswell e Creswell (2018) referiram que a investigação quantitativa procura medir fenómenos, testar hipóteses e identificar relações estatísticas entre variáveis, caracterizando-se normalmente pela utilização de dados numéricos, instrumentos padronizados e análises estatísticas.
Por outro lado referem que a investigação qualitativa procura compreender fenómenos em profundidade, explorando significados, experiências e contextos específicos. Neste tipo de metodologia os dados são frequentemente recolhidos através de entrevistas, observação ou análise documental.
Então, enquanto a investigação quantitativa responde frequentemente a questões como: “Existe relação entre as variáveis?” e “Qual o impacto de X sobre Y?”, a investigação qualitativa procura compreender questões: “Como os participantes interpretam determinado fenómeno?” e “Quais os significados atribuídos às experiências?”
1.1. Quando utilizar a Metodologia Quantitativa?
A metodologia quantitativa tende a ser mais adequada quando o investigador pretende:
• Testar hipóteses;
• Medir relações entre variáveis;
• Comparar grupos;
• Generalizar resultados;
Alguns exemplos são:
• Estudos correlacionais;
• Estudos experimentais;
• Surveys;
• Modelagem de equações estruturais;
• Estudos econométricos.
Neste contexto, análises estatísticas como regressão, ANOVA, SEM e análise multigrupos tornam-se particularmente relevantes.
1.2. Quando utilizar metodologia qualitativa?
A metodologia qualitativa tende a ser mais adequada quando o investigador pretende:
• Compreender fenómenos complexos;
• Explorar experiências subjetivas;
• Analisar contextos específicos;
• Aprofundar interpretações.
Segundo Yin (2018), abordagens qualitativas são particularmente úteis quando existe forte influência contextual ou quando o fenómeno é ainda pouco compreendido.
Alguns exemplos deste tipo de metodologias são:
• Entrevistas em profundidade;
• Grupos focais;
• Análise temática;
• Análise de conteúdo;
• Estudos etnográficos.
2. O Estudo de Caso: Uma abordagem em comum
O estudo de caso representa uma das abordagens metodológicas mais utilizadas em investigação qualitativa, embora também possa incorporar elementos quantitativos.
Segundo Yin (2018), o estudo de caso é particularmente útil quando o objetivo consiste em compreender fenómenos contemporâneos em contexto real. Anteriormente outro autor (Stake, 1995) também referiu que o mesmo permite explorar profundamente situações específicas, organizações, indivíduos ou processos complexos.
Alguns exemplos da sua aplicação incluem:
• Análise de uma empresa específica;
• Implementação de determinada tecnologia;
• Estudos clínicos;
• Processos educativos;
• Inovação organizacional.
2.1. Estudo de caso vs Investigação Quantitativa
Uma das maiores diferenças entre estudos de caso e investigação quantitativa tradicional relaciona-se com os objetivos científicos.
Na investigação quantitativa:
• Procura-se frequentemente generalização estatística;
• Utilizam-se amostras maiores;
• Existe maior foco em relações causais.
Já nos estudos de caso:
• Existe maior profundidade contextual;
• A interpretação assume maior relevância;
• A compreensão detalhada do fenómeno é prioritária.
Tal facto não significa que uma abordagem seja superior à outra, sendo que a sua escolha depende dos objetivos da investigação e das questões científicas formuladas.
3. Relação entre Metodologia e Análise Estatística
A escolha metodológica influencia diretamente a futura análise estatística.
Por exemplo:
• Estudos experimentais podem recorrer por exemplo ao Teste T ou à ANOVA;
• Estudos correlacionais utilizam regressão ou SEM;
• Estudos longitudinais podem recorrer a modelos de crescimento;
• Estudos multinível exigem frequentemente multilevel modeling;
• Estudos qualitativos recorrem à análise temática ou análise de conteúdo.
Posto isto é muito importante ter em conta que segundo Hair et al. (2022), muitos erros metodológicos ocorrem precisamente porque investigadores escolhem técnicas estatísticas sem considerar adequadamente o desenho metodológico.Apresentamos de seguida alguns dos erros metodológicos mais comuns
3.1. Erros metodológicos mais comuns
Entre os erros metodológicos mais frequentes destacam-se:
• Escolher primeiro a análise estatística e só depois a metodologia;
• Utilizar técnicas complexas sem fundamentação;
• Utilizar SEM sem teoria adequada;
• Utilizar amostras inadequadas;
• Confundir profundidade qualitativa com generalização quantitativa.
Field (2018) já nos alertou para o facto de mesmo análises estatísticas avançadas poderem produzir resultados inválidos quando o desenho metodológico é inadequado.
Conclusão
Em suma, a metodologia científica deve orientar todas as decisões relacionadas com a investigação, incluindo a futura análise estatística. A escolha entre metodologia qualitativa, quantitativa ou estudo de caso depende dos objetivos científicos, das questões de investigação e da natureza do fenómeno estudado.
Mais importante do que utilizar técnicas estatísticas complexas é garantir coerência metodológica, fundamentação teórica e adequação entre objetivos, desenho de investigação e análise dos dados.
Referências Bibliográficas
Creswell, J.W. & Creswell, J.D. (2018). Research Design: Qualitative, Quantitative, and Mixed Methods Approaches. Sage, Los Angeles.
Field, A.P. (2018). Discovering Statistics Using IBM SPSS Statistics (5th Ed). Sage, Newbury Park.
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2022). A Primer on Partial Least Squares Structural Equaton Modeling (PLS-SEM) (3rd ed.). Sage. https://doi.org/10.1007/978-3-030-80519-7
Stake, R.E. (1995). The Art of Case Study Research. Sage Publications, Thousand Oaks.Yin, R. K. (2018). Case Study Research and Applications: Design and Methods (6th Ed.). Sage Publications.
Yin, R. K. (2018). Case Study Research and Applications: Design and Methods (6th Ed.). Sage Publications.
A Evolução da Análise Estatística na Investigação Científica: Da Estatística Clássica às Novas Ferramentas de Análise de Dados

Autor: Mário Rocha
É relevante a evolução da análise estatística nas últimas décadas, acompanhando o desenvolvimento de novas metodologias, o aumento da complexidade dos dados e as exigências crescentes da investigação científica contemporânea. Embora softwares clássicos como o SPSS e o AMOS continuem amplamente utilizados no contexto académico e profissional, novas ferramentas têm vindo a ganhar destaque devido à sua flexibilidade, acessibilidade e integração com abordagens estatísticas mais modernas, apresentando um enorme contributo para a evolução da análise estatística e da metodologia ciêntifica.
Atualmente, Softwares como JASP, Jamovi, Factor, SmartPLS, R oferecem soluções cada vez mais completas para análise de dados, permitindo realizar desde análises descritivas e testes inferenciais até modelos fatoriais, análise multivariada, psicometria avançada e modelos de equações estruturais. Estas ferramentas destacam-se não apenas pela diversidade de procedimentos disponíveis, mas também pela crescente preocupação com a transparência metodológica, reprodutibilidade científica e interpretação dos resultados.
A Evolução da Análise Estatística e os Novos Softwares
Durante muitos anos, softwares como o SPSS e AMOS dominaram a investigação aplicada em áreas como Psicologia, Educação, Ciências da Saúde, Gestão e Ciências Sociais. A sua interface intuitiva e facilidade de utilização contribuíram para uma ampla disseminação da análise estatística em contextos académicos e profissionais.
Contudo, a evolução da análise estatística trouxe novas exigências metodológicas. A necessidade de integrar modelos mais complexos, análise de fiabilidade avançada, bootstrap, validação psicométrica, análise fatorial confirmatória e modelos de equações estruturais levou ao crescimento de plataformas mais flexíveis e adaptadas às abordagens estatísticas atuais.
Neste contexto, softwares gratuitos como JASP e Jamovi têm vindo a assumir um papel particularmente relevante. Estas plataformas permitem realizar análises estatísticas robustas através de interfaces intuitivas, aproximando procedimentos metodológicos mais avançados de investigadores com diferentes níveis de experiência estatística. É importante destacar também softwares mais específicos como o Factor para análise fatorial exploratória.
Além disso, ferramentas como o SmartPLS tornaram-se especialmente relevantes no contexto dos modelos de equações estruturais baseados em variância (PLS-SEM), sendo frequentemente utilizadas em estudos exploratórios, modelos preditivos e investigação aplicada em áreas multidisciplinares.
Reprodutibilidade Científica e Transparência Metodológica
Um dos aspetos mais relevantes na evolução recente da análise estatística relaciona-se com a crescente preocupação com a reprodutibilidade científica. Atualmente, não basta apenas apresentar resultados estatísticos. É igualmente importante justificar as opções metodológicas adotadas, garantir coerência entre objetivos, hipóteses e análises realizadas, bem como assegurar transparência na interpretação dos resultados.
Neste sentido, softwares como R, JASP e Jamovi têm contribuído para aproximar a investigação científica de práticas metodológicas mais transparentes e reprodutíveis. A integração de relatórios automáticos, sintaxe, outputs organizados e documentação mais clara facilita não apenas a análise dos dados, mas também a revisão crítica dos procedimentos utilizados.
A Importância da Interpretação Metodológica
Apesar da evolução tecnológica e do aparecimento de ferramentas estatísticas cada vez mais avançadas, nenhum software substitui a necessidade de compreensão metodológica. A escolha do teste estatístico, a avaliação dos pressupostos, a interpretação dos resultados e a adequação entre modelo teórico e análise empírica continuam a ser elementos centrais para a qualidade científica da investigação.
Assim, mais importante do que utilizar um software específico é compreender a lógica metodológica subjacente às análises realizadas. Diferentes programas podem produzir resultados semelhantes, mas a qualidade da investigação dependerá sempre da coerência conceptual, da fundamentação estatística e da interpretação crítica dos dados.
Considerações Finais
A evolução da análise estatística reflete não apenas avanços tecnológicos, mas também mudanças profundas na forma como a investigação científica é conduzida e interpretada. O crescimento de softwares como JASP, Jamovi, SmartPLS e R demonstra uma tendência crescente para metodologias mais acessíveis, flexíveis e alinhadas com os princípios atuais da ciência aberta e da reprodutibilidade.
Neste espaço procuramos precisamente acompanhar essa evolução metodológica, conciliando abordagens estatísticas clássicas com ferramentas mais recentes, sempre com foco na clareza, rigor científico e adequação das análises aos objetivos concretos de cada investigação.
Precisa de apoio em análise estatística, metodologia ou validação de instrumentos? Entre em contacto.
Outros Artigos Relevantes
JASP e Jamovi vs SPSS: Comparação Técnica, Vantagens e Aplicações Académicas
Construção e Adaptação de Questionários: Fundamentos Metodológicos e Validação
Estatística e Consultoria em Análise Estatística: Importância para a Investigação e Empresas
Estatística para Empresas: Como a Análise de Dados Melhora Decisões e Resultados
Validade de Conteúdo em Questionários: Como aplicar e principais índices (CVR, CVI e V de Aiken)
Autor: Mário Rocha e Flávia Negrini
A validade de conteúdo em questionários é uma etapa essencial no processo de construção e adaptação de questionários. É uma etapa central no desenvolvimento e adaptação de instrumentos de medida, sendo amplamente reconhecida como a base para as restantes formas de validade.
Tal como referido por Haynes, Richard e Kubany (1995), refere-se ao grau em que os itens representam adequadamente o construto que se pretende medir. Esta perspetiva é reforçada por abordagens mais recentes, que sublinham que sem validade de conteúdo dificilmente se pode garantir validade de construto ou de critério.
Neste artigo apresentamos uma visão geral do processo, sendo os procedimentos específicos aprofundados em artigos dedicados.
1. O que é a validade de conteúdo em questionários?
A validade de conteúdo implica assegurar que os itens são relevantes, claros e representativos do domínio do construto. Não se trata apenas de uma avaliação superficial, mas de um processo sistemático de alinhamento entre teoria e medição. Autores como Delgado-Rico et al. (2012) destacam que esta validade envolve múltiplas dimensões, incluindo a representatividade do conteúdo e a adequação da formulação dos itens. De forma complementar, estudos recentes sublinham a importância de considerar também o contexto cultural e a população-alvo.
2. Processo de Avaliação de Conteúdo
O processo de validade de conteúdo em questionários envolve geralmente:
- Teste Blueprint
- Seleção de especialistas
- Avaliação dos itens (relevância, clareza)
- Cálculo de índices
- Revisão dos itens
Este processo deve ser devidamente documentado em trabalhos científicos.
2.1. Planeamento do instrumento (test blueprint)
Antes da avaliação por especialistas, é essencial um planeamento rigoroso do instrumento. Neste contexto, o test blueprint assume particular relevância, funcionando como um mapa conceptual que orienta a construção dos itens.
Este blueprint define o construto, as suas dimensões e a forma como os itens são distribuídos, garantindo coerência e cobertura adequada.
Dada a sua importância, este tema será aprofundado num artigo específico dedicado ao desenvolvimento de instrumentos.
2.2. Seleção de especialistas e considerações práticas
A seleção de especialistas é um dos pontos mais críticos na validade de conteúdo. A literatura sugere frequentemente entre 3 a 5 especialistas em fases iniciais, podendo este número aumentar para 5 a 10 em estudos mais robustos (Lynn, 1986; Polit & Beck, 2006; Roebianto et al., 2023).
No entanto, mais importante do que o número é a qualidade dos especialistas, nomeadamente a sua experiência científica e conhecimento do construto.
Adicionalmente, importa considerar a inclusão de participantes da população-alvo, especialmente para avaliar a clareza e compreensão dos itens. Esta ligação entre especialistas e utilizadores finais conduz naturalmente à importância do estudo piloto.
2.3. Principais índices para avaliação da validade de conteúdo em questionários
Os principais índices utilizados são:
- CVR (Content Validity Ratio)
- CVI (Content Validity Index)
- V de Aiken
- Coeficientes de concordância
Valores mais elevados indicam maior concordância entre especialistas.
Cada um destes índices apresenta características específicas e diferentes formas de interpretação. Dada a sua complexidade e importância, serão abordados em artigos dedicados, permitindo uma explicação detalhada e aplicação prática. A interpretação deve ser feita com base na literatura e no contexto do estudo.
3. Evidência empírica: alguns estudos com aplicação da validade de conteúdo em questionários
A análise de estudos empíricos recentes mostra uma forte consistência na forma como a validade de conteúdo é aplicada.
De forma geral, os estudos utilizam painéis de especialistas entre 5 e 10 elementos, aplicam escalas de avaliação de relevância e clareza e recorrem a índices como o CVI e o CVR para quantificar os resultados. Após esta fase, é comum a revisão ou eliminação de itens com base nos critérios definidos.
Alguns estudos de adaptação cultural evidenciam a importância desta etapa na garantia de equivalência semântica e conceptual, mostrando que a validade de conteúdo é essencial antes da realização de análises fatoriais.
Outros trabalhos demonstram que, mesmo quando os índices apresentam valores elevados, a revisão qualitativa dos itens continua a ser necessária, reforçando a ideia de que a validade de conteúdo deve integrar abordagens quantitativas e qualitativas.
Segue em baixo as referências de alguns estudos recentes realizados em Portugal e a nível internacional com aplicação da validade de conteúdo em questionários.
- Dalawi, I, Isa, M., Chen, X., Azhar, Z., & Aimran, N. (2023). Development of the Malay Language of understanding, attitude, practice and health literacy questionnaire on COVID-19 (MUAPHQ C-19): content validity & face validity analysis. BMC Public Health, 23. https://doi.org/10.1186/s12889-023-16044-5
- Loureiro, A., Ibanez-Cubillas, P., Miranda-Pinto, M. (2024). Validade de Conteúdo por avaliação de especialistas para medir as competências digitais de estudantes de mestrado em Educação Especial. Texto Livre, 17. https://doi.org/10.1590/1983-3652.2024.52564
- Martins, M., Paiva-Santos, F., Todo Bom, L., Dixe, M. dos A., & Costeira, C. (2025). Cultural adaptation and content validation of the RAC (Rodríguez-Almeida-Cañon) adult infection risk assessment scale for Portuguese from Portugal. Millenium – Journal of Education, Technologies, and Health, 2(28). https://doi.org/10.29352/mill0228.41505
- Moreira, W., Campos, L., Dias, P., & Nóbrega, M. (2025). Adaptation and content validity of the Brazilian version of the Mental Health Literacy questionnaire. Rev Bras Enferm, 78(4). https://doi.org/10.1590/0034-7167-2024-0309pt
- Vilhena, D., Guimarães, M., Guimarães, R., & Pinheiro, A. (2023). Validade de Conteúdo e Fidedignidade do Teste de Taxa de Leitura. Avaliação Psicológica, 22 (2). https://doi.org/10.15689/ap.2023.2202.22980.10
- Trindade, C., Kato, S., Gurgel, L., & Reppold, C. (2018). Processo de Construção e Busca de Evidências de Validade de Conteúdo da Equalis-OAS. Avaliação Psicológica, 17(2), 271-277. https://doi.org/10.15689/ap.2018.1702.14501.13
4. Recomendações práticas
- A validade de conteúdo em questionários deve ser realizada antes do estudo piloto.
- É importante justificar decisões e reportar resultados de forma transparente.
Referências Bibliográficas
Haynes, S., Richard, D., & Kubany, E. (1995). Content validity in psychological assessment: A functional approach to concepts and methods. Psychological Assessment, 7(3), 238–247. https://doi.org/10.1037/1040-3590.7.3.238
Lynn, M. (1986). Determination and quantification of content validity. Nursing Research, 35(6), 382–386. https://doi.org/10.1097/00006199-198611000-00017
Polit, D., & Beck, C. (2006). The content validity index: Are you sure you know what’s being reported? Critique and recommendations. Research in Nursing & Health, 29 (5), 489–497. https://doi.org/10.1002/nur.20147
Polit, D., Beck, C., Owen, S. (2007). Is the CVI an acceptable indicator of content validity? Appraisal and recommendations. Research in Nursing Health, 30 (4), 459-467. https://doi.org/10.1002/nur.20199
Delgado-Rico, E., Carrctero-Dios, H., & Ruch, W. (2012). Content validity evidences in test development: An applied perspective International. Journal of Clinical and Health Psychology, 12 (3), 449-459. https://www.researchgate.net/publication/279618267_Content_validity_evidences_in_test_development_An_applied_perspective
Robianto, A., Savitri, S., Aulia, I., Suciyana, A., & Mubarokah, L. (2023). Content Validity: Definition and Procedure of Content Validation in Psychological Research. TPM, 30 (1), 5-18. https://doi.org/10.4473/TPM30.1.1
Construção e Adaptação de Questionários: Fundamentos Metodológicos e Validação Estatística

Autor: Mário Rocha
A construção e adaptação de questionários é um processo metodológico rigoroso que envolve definição conceptual clara, desenvolvimento sistemático de itens e validação estatística das propriedades psicométricas do instrumento.
Etapas da Construção e Adaptação de Questionários
No presente artigo apresentamos algumas noções mais gerais de todo este processo, que depois iremos explicar de modo mais detalhado em diversos outros artigos.
1. Definição Conceptual e Operacionalização do Construto
O processo inicia-se com a definição teórica do construto com base na literatura científica. A operacionalização implica traduzir conceitos abstratos em indicadores observáveis. Segundo DeVellis (2016), a clareza conceptual é condição essencial para garantir validade de construto.
2. Criação e Refinamento de Itens
A criação inicial de itens deve basear-se em revisão de literatura, entrevistas exploratórias ou adaptação de escalas previamente validadas. Hinkin (1998) recomenda a criação de um conjunto alargado de itens iniciais, seguido de avaliação e eliminação progressiva.
3. Validade de Conteúdo em questionários ciêntificos
A validade de conteúdo avalia a representatividade dos itens face ao construto. Este processo envolve juízes especialistas e pode recorrer ao cálculo do Content Validity Index (CVI).
O cálculo do CVI e do CVR será explicado detalhadamente num artigo específico dedicado à validade de conteúdo.
4. Estudo Piloto
A aplicação piloto permite avaliar clareza semântica, tempo de resposta e consistência preliminar. Esta fase contribui para o refinamento final do instrumento. Uma explicação mais detalhada será dada num artigo mais especifico.
5. Validade de Construto
Esta fase implica a obtenção e/ou validação de uma estrutura fatorial. Realiza-se geralmente através de dois processos estatísticos que são a análise fatorial exploratória (AFE) e análise fatorial confirmatória (AFC), e também pela análise da validade convergente e divergente. É importante realçar que a utilização de AFE e depois AFC é mais comum em processos de construção e adaptação de questionários, sendo a AFC isolada mais comum quando se pretende apenas validar determinada estrutura fatorial já anteriormente validada e definida.
Este processo, assim como as análises mais especificas que o definem também serão alvo de artigos explicativos mais especificos
5.1. Análise Fatorial Exploratória (AFE)
A AFE permite identificar a estrutura latente dos dados. Recomenda-se verificar a adequação da amostra através do índice KMO e do teste de esfericidade de Bartlett. Segundo Worthington e Whittaker (2006) e Hair et al. (2019) é necessário ter em conta as cargas fatoriais dos itens nos fatores para a definição correcta dos mesmos.
Num artigo próprio abordaremos passo a passo a AFE, incluindo interpretação do KMO, teste de Bartlett , critérios de retenção de fatores e de agrupamento de itens no fator respetivo.
5.2. Análise Fatorial Confirmatória (AFC)
A AFC testa empiricamente o modelo de medida previamente definido. Autores como Hair et al. (2019) e Kline (2016) sugerem avaliar índices de ajustamento para validação do modelo de medida. Existem intervalos de valores que diferem de acordo com diferentes autores, que passaremos a discutir num artigo mais específico.
6. Validade Convergente e Discriminante
A validade convergente pode ser avaliada pela Average Variance Extracted (AVE ). A validade discriminante pode ser examinada pelo critério de Fornell-Larcker ou pelo rácio HTMT. Para este caso também existem valores de referência que passamos a explicar num artigo mais especifico.
7. Avaliação da Fiabilidade
A consistência interna é tradicionalmente avaliada através do alfa de Cronbach, existindo porém outros metodos de análise da fiabilidade como o teste-reteste. Em contextos confirmatórios, para a análise da consistência interna recomenda-se também a fiabilidade composta (CR) e o coeficiente omega.
As várias medidas de análise da fiabilidade fatorial, assim como os seus principais indicadores (alfa de Cronbach, omega, fiabilidade composta) serão aprofundados num artigo dedicado.
9. Adaptação Transcultural de Instrumentos de Medida
A adaptação de instrumentos para novos contextos culturais deve seguir procedimentos de tradução e retrotradução. Beaton et al. (2000) e a International Test Commission (2017) fornecem diretrizes metodológicas detalhadas para esse processo. Para além disso também é importante o recurso a validade de conteúdo, realização de estudo piloto e também a análise da validade de construto e da fiabilidade.
O processo de tradução e retrotradução será explicado detalhadamente num artigo específico sobre adaptação transcultural.
10. Como reportar em Teses e Artigos Científicos
O relato académico deve incluir descrição do construto, procedimentos de desenvolvimento, resultados das análises fatoriais, índices de ajustamento, medidas de fiabilidade e evidências de validade. O Publication Manual da APA (2020) recomenda transparência e apresentação completa dos resultados.
Referências
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.).
Beaton, D. E., et al. (2000). Guidelines for the process of cross-cultural adaptation of self-report measures. Spine, 25(24), 3186–3191.
DeVellis, R. F. (2016). Scale development: Theory and applications (4th ed.). Sage.
Hair, J. F., et al. (2019). Multivariate data analysis (8th ed.). Cengage.
Hinkin, T. R. (1998). A brief tutorial on the development of measures. Organizational Research Methods, 1(1), 104–121.
International Test Commission. (2017). The ITC guidelines for translating and adapting tests (2nd ed.).
Kline, R. B. (2016). Principles and practice of structural equation modeling (4th ed.). Guilford Press.
Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric theory (3rd ed.). McGraw-Hill.
Worthington, R. L., & Whittaker, T. A. (2006). Scale development research. The Counseling Psychologist, 34(6), 806–838.
JASP e Jamovi vs SPSS: Comparação Técnica, Vantagens e Aplicações Académicas

Autor: Mário Rocha
Nos últimos anos, o panorama da análise estatística académica tem evoluído significativamente. Embora o SPSS continue a ser amplamente utilizado, ferramentas open-source como o JASP e o Jamovi têm vindo a ganhar relevância devido à sua robustez, transparência e alinhamento com os princípios de ciência aberta.
1. Base Estatística: Integração com R
Tanto o JASP como o Jamovi são baseados em R (R Core Team), o que garante robustez matemática, transparência nos algoritmos e atualização contínua da comunidade científica. A utilização do motor R permite que os cálculos estatísticos sejam sustentados por bibliotecas validadas internacionalmente.
2. JASP – Características Avançadas
O JASP integra estatística clássica e bayesiana numa interface intuitiva. Inclui testes t, ANOVA, regressões lineares e logísticas, análises fatoriais, modelos mistos e SEM.
Uma vantagem distintiva é a integração nativa de estatística bayesiana, permitindo cálculo de Bayes Factors sem necessidade de módulos externos.
3. Jamovi – Estrutura Modular
O Jamovi apresenta interface semelhante ao SPSS, facilitando a adaptação. Permite análises descritivas, inferenciais, regressões, AFE, AFC e modelos lineares gerais.
Através de módulos adicionais, é possível realizar mediação, moderação e modelos estruturais.
4. Comparação Técnica Estruturada
| Critério | SPSS | JASP | Jamovi |
| Custo | Pago | Gratuito | Gratuito |
| Base Estatística | Proprietária | Base R (Open-source) | Base R (Open-source) |
| Estatística Bayesiana | Limitada | Integrada | Disponível via módulos |
| Reprodutibilidade | Limitada | Elevada | Elevada |
| Atualizações | Dependente de licenciamento | Frequentes | Frequentes |
5. Vantagens para Investigação Académica
A utilização de softwares gratuitos reduz barreiras económicas, promove maior acessibilidade e está alinhada com práticas contemporâneas de ciência aberta e reprodutibilidade científica.
6. Posicionamento Estratégico
Para estudantes e investigadores que desenvolvem teses, dissertações ou artigos científicos, JASP e Jamovi representam soluções modernas, robustas e metodologicamente adequadas. A escolha do software deve estar alinhada com os objetivos do estudo, tipo de análise e contexto institucional.
7. Alguns artigos interessantes a ter em conta sobre Jasp e Jamovi
Tem sido já diversos os estudos realizados sobre o funcionamento e com a utilização destes softwares, como por exemplo:
- Coffee, Data and Jamovi: The Perfect Recipe for great Statistical Analysis – Artigo de 2025 sobre o jamovi e as suas caracteristicas e funcionalidades. (https://doi.org/10.37497/jsim.v12.id178.2025)
- A review of user-friendly freely-available statistical analysis software for medical researchers and biostatisticians – Artigo de 2024 sobre softwares frequentemente utilizados em pesquisas médicas como o caso do Jasp e Jamovi (https://doi.org/10.1080/27684520.2024.2322630)
- Sport anxiety and subjective happiness of college athletes– Estudo realizado em 2024 com recurso ao SPSS e Jasp para análise estatística de dados. (https://doi.org/10.3389/fpsyg.2024.1400094)
- Enhancing Student’s Performance and Attitude in Statistics Through the Use of Jamovi Software – Estudo realizado em 2025 sobre o impacto do uso do jamovi na performance e e atitudes dos estudantes (https://www.ejournals.ph/article.php?id=30783)
- Energy Expenditure of Special Forces Soldiers in Relation to External Load– Estudo de 2025 em que foi utilizado o Jamovi para análise estatística. (https://doi.org/10.3390/nu18010027)
- We Need Engaged Workers! A Structural Equation Modeling Study from the Positive Organizational Psychology in Times of COVID-19 in Chile – Estudo de 2022 em que foi utilizado o Jasp para a análise estatística de dados. (https://doi.org/10.3390/ijerph19137700)
- Structural Equation Modeling (SEM) in Jamovi: An example of analyzing the impact of factors on enterprise innovation activity – Estudo de 2025 desenvolvido com o apoio estatistico do Jamovi. (https://doi.org/10.35784/acs_7037)
Conclusão
JASP e Jamovi não são apenas alternativas gratuitas ao SPSS, mas ferramentas estatísticas com potencial técnico elevado, sustentadas por R e alinhadas com a evolução da investigação científica contemporânea.
p-valor, Effect Size e Intervalos de Confiança: Interpretação e Valores de Referência

Autor: Mário Rocha
O p-valor, o tamanho do efeito (effect size) e os intervalos de confiança são três componentes centrais da inferência estatística. Apesar de frequentemente utilizados em conjunto, representam conceitos distintos e complementares. A sua correta interpretação é fundamental na investigação científica e na elaboração de teses, dissertações e artigos académicos.
1. O p-valor: Definição e Interpretação
O p-valor representa a probabilidade de observar resultados tão extremos quanto os obtidos, assumindo que a hipótese nula é verdadeira. Importa salientar que o p-valor não representa a probabilidade da hipótese nula ser verdadeira, nem mede a magnitude do efeito observado.
A prática convencional tem utilizado o nível de significância α = 0,05 como critério de decisão. No entanto, conforme salientado pela American Statistical Association (ASA), o p-valor não deve ser utilizado como único critério para conclusões científicas (Wasserstein & Lazar, 2016).
2. Tamanho do Efeito (Effect Size)
O tamanho do efeito quantifica a magnitude da diferença ou associação observada. Ao contrário do p-valor, o effect size não depende diretamente do tamanho da amostra.
Cohen (1988) propôs valores de referência amplamente utilizados para o d de Cohen: d ≈ 0,2 (pequeno), 0,5 (moderado) e 0,8 (grande). Estes valores são indicativos e devem ser interpretados no contexto específico da área científica.
Lakens (2013) reforça a importância de reportar medidas de tamanho do efeito para permitir comparações entre estudos e meta-análises.
3. Intervalos de Confiança
Os intervalos de confiança (IC) fornecem um intervalo plausível de valores para o parâmetro populacional. Um IC de 95% indica que, em amostragens repetidas, 95% dos intervalos construídos conteriam o verdadeiro parâmetro.
Cumming (2014) argumenta que os intervalos de confiança devem ser privilegiados em detrimento da interpretação exclusiva baseada no p-valor, por fornecerem informação sobre precisão e magnitude.
4. Integração dos Três Elementos
A interpretação adequada de resultados estatísticos deve integrar: (1) significância estatística (p-valor), (2) magnitude do efeito (effect size), e (3) precisão da estimativa (intervalo de confiança).
5. Como reportar em Teses e Artigos Científicos
Segundo o Publication Manual of the American Psychological Association (2020), devem ser reportados valores exatos de p (por exemplo, p = 0,032), juntamente com o tamanho do efeito e, sempre que possível, intervalos de confiança.
Exemplo de reporte adequado: ‘Verificou-se uma diferença estatisticamente significativa entre os grupos, t(98) = 2,45, p = 0,016, d = 0,49, IC95% [0,10, 0,88].’
Referências
American Psychological Association. (2020). Publication manual of the American Psychological Association (7th ed.).
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Cumming, G. (2014). The new statistics: Why and how. Psychological Science, 25(1), 7–29.
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science. Frontiers in Psychology, 4, 863.
Wasserstein, R. L., & Lazar, N. A. (2016). The ASA’s statement on p-values. The American Statistician, 70(2), 129–133.
Estatística para Empresas: Como a Análise de Dados Melhora Decisões e Resultados

Autor: Mário Rocha e Flávia Negrini
A estatística aplicada às empresas é uma ferramenta estratégica fundamental para melhorar a tomada de decisão, reduzir riscos e aumentar a competitividade. Num contexto empresarial cada vez mais orientado por dados, a capacidade de recolher, analisar e interpretar informação quantitativa pode determinar o sucesso ou fracasso de um projeto, produto ou estratégia de mercado.
1. O Papel da Estatística na Gestão Empresarial
A estatística permite transformar dados brutos em informação útil para suporte à decisão. Através de métodos descritivos e inferenciais, as empresas conseguem identificar padrões de consumo, avaliar desempenho, medir satisfação de clientes e prever tendências futuras.
A utilização de indicadores estatísticos contribui para decisões baseadas em evidência, em vez de intuição isolada.
2. Principais Aplicações da Estatística nas Empresas
Entre as aplicações mais relevantes destacam-se:
– Estudos de mercado e análise de comportamento do consumidor
– Avaliação de desempenho organizacional
– Análise de risco e previsão financeira
– Testes de hipóteses para comparação de estratégias
– Modelos preditivos para planeamento estratégico
3. Estatística Descritiva e Inferencial no Contexto Empresarial
A estatística descritiva resume e organiza dados através de médias, medianas, desvio padrão e gráficos. Já a estatística inferencial permite tirar conclusões sobre populações com base em amostras, utilizando testes estatísticos, intervalos de confiança e modelos preditivos.
A combinação destas abordagens fornece uma visão robusta da realidade empresarial.
4. Benefícios da Análise Estatística para Empresas
– Redução da incerteza na tomada de decisão
– Identificação de oportunidades de crescimento
– Otimização de processos internos
– Melhor segmentação de clientes
– Avaliação objetiva de estratégias implementadas
5. A Importância da Qualidade dos Dados
A qualidade da análise depende diretamente da qualidade dos dados recolhidos. Erros de amostragem, viés ou inconsistências podem comprometer resultados e decisões estratégicas. Por isso, é essencial aplicar métodos estatísticos adequados e garantir rigor metodológico.
6. Estatística e Transformação Digital
Com o crescimento da digitalização, as empresas geram grandes volumes de dados. A estatística é a base que sustenta técnicas mais avançadas como análise preditiva e inteligência artificial, permitindo transformar dados em vantagem competitiva.
Conclusão
A estatística para empresas não é apenas uma ferramenta técnica, mas um instrumento estratégico de gestão. Empresas que adotam uma cultura orientada por dados conseguem tomar decisões mais informadas, reduzir riscos e melhorar resultados de forma sustentável.
Se pretende aplicar análise estatística na sua empresa, desenvolver estudos de mercado ou avaliar estratégias com base em dados concretos, um acompanhamento especializado pode garantir maior rigor e eficiência nos resultados.
Diferença entre p-valor e Effect Size: Significância Estatística vs Magnitude do Efeito

Autor: Mário Rocha
A distinção entre p-valor e tamanho do efeito (effect size) é fundamental para uma interpretação rigorosa dos resultados estatísticos em investigação científica. Embora frequentemente reportados em conjunto, estes dois indicadores respondem a questões diferentes. Enquanto o p-valor informa sobre evidência contra a hipótese nula, o effect size quantifica a magnitude real da diferença ou relação observada.
1. O que mede o p-valor?
O p-valor representa a probabilidade de obter um resultado igual ou mais extremo do que o observado, assumindo que a hipótese nula (H0) é verdadeira. Se p ≤ α (tipicamente 0,05), rejeita-se H0. No entanto, o p-valor não indica a magnitude do efeito nem a sua relevância prática.
Conforme destacado pela American Statistical Association (ASA), o p-valor não mede a importância de um resultado nem a probabilidade de uma hipótese ser verdadeira (Wasserstein & Lazar, 2016).
2. O que é o Effect Size?
O tamanho do efeito (effect size) quantifica a magnitude da diferença entre grupos ou a força da relação entre variáveis. Exemplos comuns incluem o d de Cohen, eta quadrado (η²), r de Pearson e odds ratio.
O effect size responde à pergunta: ‘Quão grande é o efeito observado?’ Enquanto o p-valor responde apenas se o efeito é estatisticamente detetável.
3. Porque o p-valor não é suficiente?
O p-valor é fortemente influenciado pelo tamanho da amostra. Em amostras muito grandes, efeitos pequenos podem tornar-se estatisticamente significativos. Por outro lado, em amostras pequenas, efeitos relevantes podem não atingir significância estatística.
Por essa razão, investigadores como Cohen (1988) defenderam a necessidade de reportar sempre medidas de tamanho do efeito juntamente com testes de significância.
4. Interpretação conjunta: boa prática científica
A interpretação adequada de resultados estatísticos deve considerar simultaneamente:
– p-valor (evidência estatística)
– Effect size (magnitude do efeito)
– Intervalos de confiança
– Enquadramento teórico e relevância prática
A literatura recente reforça que decisões científicas não devem basear-se exclusivamente num limiar arbitrário de significância (Cumming, 2014; Lakens, 2013).
5. Exemplo prático
Imagine um estudo que compara dois métodos de ensino. O teste t apresenta p = 0,001, indicando diferença estatisticamente significativa. No entanto, o d de Cohen = 0,15, o que corresponde a um efeito pequeno. Neste caso, apesar da significância estatística, a relevância prática pode ser limitada.
Conclusão
A distinção entre p-valor e effect size é crucial para garantir rigor metodológico. O p-valor indica evidência contra a hipótese nula; o effect size informa sobre a magnitude do fenómeno observado. Uma investigação estatisticamente sólida deve reportar ambos e interpretar os resultados de forma integrada.
Referências
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Cumming, G. (2014). The new statistics: Why and how. Psychological Science, 25(1), 7–29. https://doi.org/10.1177/0956797613504966
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science. Frontiers in Psychology, 4, 863. https://doi.org/10.3389/fpsyg.2013.00863
Wasserstein, R., & Lazar, N. (2016). The ASA statement on p-values: Context, process, and purpose. The American Statistician, 70(2), 129–133. https://doi.org/10.1080/00031305.2016.1154108
Interpretação Correta do p-valor: Erros Comuns e Boas Práticas

Autor: Mário Rocha
O p-valor é um dos conceitos mais utilizados – e simultaneamente mais mal interpretados – na análise estatística inferencial. Em teses, dissertações e artigos científicos, uma interpretação incorreta do p-valor pode comprometer a validade das conclusões e enfraquecer a qualidade metodológica do estudo. Neste artigo, explicamos de forma técnica e fundamentada o que realmente significa o p-valor, quais os erros mais comuns na sua interpretação e como utilizá-lo corretamente no contexto da investigação científica.
O que é o p-valor?
O p-valor representa a probabilidade de obter um resultado igual ou mais extremo do que o observado, assumindo que a hipótese nula (H0) é verdadeira. Isto significa que o p-valor é sempre calculado sob a suposição de que não existe efeito, diferença ou relação na população.
Se o p-valor for inferior ao nível de significância previamente definido (normalmente α = 0,05), rejeita-se a hipótese nula. Caso contrário, não se rejeita H0. Importa sublinhar que ‘não rejeitar H0’ não significa aceitar H0 como verdadeira.
Erro 1: Interpretar o p-valor como a probabilidade da hipótese ser verdadeira
Um dos erros mais frequentes é afirmar que um p-valor de 0,03 significa que existe 3% de probabilidade da hipótese nula ser verdadeira. Esta interpretação está incorreta. O p-valor não fornece a probabilidade de H0 ser verdadeira, mas sim a probabilidade dos dados observados ocorrerem assumindo que H0 é verdadeira.
Erro 2: Confundir significância estatística com relevância prática
Um resultado estatisticamente significativo não implica necessariamente relevância prática ou importância clínica. Com amostras grandes, pequenas diferenças podem produzir p-valores muito baixos, mesmo quando o efeito é pouco relevante. Por isso, é essencial complementar a análise com medidas de tamanho de efeito.
Erro 3: Considerar 0,051 como totalmente diferente de 0,049
A interpretação rígida do limiar de 0,05 pode levar a conclusões artificiais. Um p-valor de 0,049 e outro de 0,051 representam evidências muito semelhantes contra H0. A decisão estatística não deve ser vista como um interruptor binário, mas como parte de uma análise mais ampla.
Boas Práticas na Interpretação do p-valor
Para garantir rigor científico, recomenda-se:
– Definir o nível de significância antes da análise
– Reportar o valor exato do p-valor
– Apresentar medidas de tamanho de efeito
– Interpretar os resultados no contexto teórico do estudo
– Evitar conclusões absolutas baseadas apenas no p-valor
Como Reportar o p-valor em Trabalhos Académicos
Segundo normas académicas como APA, o p-valor deve ser apresentado com três casas decimais (por exemplo, p = 0,032). Quando o valor for inferior a 0,001, pode reportar-se como p < 0,001.
Conclusão
O p-valor é uma ferramenta fundamental na estatística inferencial, mas deve ser interpretado com rigor e cautela. A sua utilização isolada pode levar a interpretações erradas. Uma análise estatística robusta exige consideração conjunta de pressupostos, tamanho de efeito, intervalo de confiança e enquadramento teórico.
Se necessita de apoio na interpretação correta de resultados estatísticos na sua tese ou investigação científica, um acompanhamento especializado pode garantir maior rigor e segurança metodológica.
Entre em contacto connosco para mais informações
Como Fazer um Teste de Hipóteses na Prática: Pequeno Guia Passo a Passo

Autor: Mário Rocha
Depois de compreender os conceitos fundamentais, é importante saber aplicar corretamente um teste de hipóteses. Aqui apresentamos um guia prático passo a passo.
Passo 1 – Definir a pergunta de investigação
A pergunta deve ser clara, específica e mensurável. Exemplo: ‘Existe diferença significativa entre dois grupos independentes?’
Passo 2 – Formular H0 e H1
Definir corretamente as hipóteses é essencial para orientar toda a análise estatística.
Passo 3 – Escolher o teste estatístico adequado
Alguns testes comuns incluem:
– Teste t (comparação de médias)
– ANOVA (comparação de médias de três ou mais grupos)
– Qui-quadrado (Teste de associação entre variáveis categóricas)
– Testes não paramétricos (quando pressupostos não são cumpridos)
Passo 4 – Verificar pressupostos
Antes de aplicar o teste, deve verificar normalidade, homogeneidade de variâncias e independência das observações.
Passo 5 – Calcular o p-valor e interpretar
Após aplicar o teste, compare o p-valor com o nível de significância e interprete os resultados no contexto do estudo.
Erros mais comuns
– Interpretar mal o p-valor
– Escolher o teste errado
– Ignorar pressupostos
– Confundir significância estatística com relevância prática
Tem alguma dúvida ou necessidade de esclarecimento ou apoio nas suas análises?
Entre em contacto Connosco!!
Teste de Hipóteses na Estatística: Guia Resumo, Simples e Aplicado
Autor: Mário Rocha
Os testes de hipóteses são uma das ferramentas mais importantes da estatística inferencial. Eles permitem tomar decisões baseadas em dados, reduzindo a incerteza e aumentando a validade científica das conclusões. Se está a desenvolver uma tese, dissertação ou projeto empresarial, compreender corretamente os testes de hipóteses é essencial.
O que é um Teste de Hipóteses?
Um teste de hipóteses é um procedimento estatístico utilizado para avaliar uma afirmação sobre uma população com base numa amostra. O objetivo é verificar se existe evidência suficiente para rejeitar uma hipótese inicial.
Hipótese Nula (H0) e Hipótese Alternativa (H1)
A hipótese nula (H0) representa a situação de referência ou ausência de efeito. A hipótese alternativa (H1) representa a existência de diferença, efeito ou relação.
Exemplo prático:
H0: A média de satisfação dos clientes não mudou.
H1: A média de satisfação dos clientes mudou.
Nível de Significância (α)
O nível de significância (geralmente 0,05) representa a probabilidade de cometer um erro ao rejeitar a hipótese nula quando esta é verdadeira.
O que é o p-valor?
O p-valor indica a probabilidade de obter resultados iguais ou mais extremos do que os observados, assumindo que a hipótese nula é verdadeira. Se o p-valor for inferior ao nível de significância, rejeita-se H0.
Erro Tipo I e Erro Tipo II
Erro Tipo I: Rejeitar H0 quando ela é verdadeira.
Erro Tipo II: Não rejeitar H0 quando ela é falsa.
Para mais informações e apoio técnico para o seu projecto entre em contacto connosco!!
Inteligência Artificial e Estatística: Uma Relação Fundamental

Autor: Mário Rocha
Introdução
A Inteligência Artificial (IA) tem vindo a assumir um papel central na transformação digital de organizações e na produção de conhecimento científico. Contudo, por detrás de muitos sistemas de IA encontram-se princípios estatísticos sólidos. A relação entre estatística e inteligência artificial é estrutural, sendo a estatística a base metodológica que sustenta grande parte dos algoritmos de aprendizagem automática.
1. A Estatística como Base da Aprendizagem Automática
A aprendizagem automática (machine learning) assenta na capacidade de identificar padrões a partir de dados. Modelos como regressão linear, regressão logística e árvores de decisão têm origem em fundamentos estatísticos. Mesmo técnicas mais avançadas, como redes neuronais, dependem de conceitos como probabilidade, inferência e otimização.
A estatística fornece os instrumentos necessários para estimar parâmetros, avaliar incerteza e validar modelos. Sem estes elementos, os sistemas de IA seriam meros mecanismos de ajuste sem rigor metodológico.
2. Probabilidade, Inferência e Validação de Modelos
A teoria das probabilidades constitui um dos pilares comuns entre estatística e IA. A modelação de incerteza, a avaliação de risco e a previsão de resultados futuros dependem de distribuições probabilísticas e métodos inferenciais.
A validação de modelos é outro ponto de interseção crucial. Técnicas como validação cruzada, métricas de desempenho e análise de erro são fundamentais tanto em estatística aplicada como em inteligência artificial.
3. Aplicações Académicas e Empresariais
No contexto académico, a integração entre IA e estatística permite analisar grandes volumes de dados e extrair conhecimento relevante. Em ambiente empresarial, a combinação destas áreas viabiliza modelos preditivos, segmentação de clientes, deteção de padrões de consumo e apoio à tomada de decisão estratégica.
Contudo, a aplicação responsável da IA requer compreensão estatística adequada. A interpretação incorreta de resultados ou a utilização de modelos sem validação rigorosa pode conduzir a conclusões enviesadas.
Conclusão
A Inteligência Artificial e a Estatística não são áreas concorrentes, mas complementares. A estatística fornece o rigor metodológico e a base teórica que sustentam muitos sistemas de IA. Para investigadores e empresas, compreender esta relação é essencial para desenvolver soluções tecnicamente robustas e metodologicamente fundamentadas.
Consultoria em Análise Estatística: Importância para a Investigação e Empresas

Autor: Mário Rocha
Introdução
Num contexto cada vez mais orientado por dados, a capacidade de analisar informação de forma rigorosa tornou-se um fator determinante tanto na investigação académica como na gestão empresarial. A análise estatística deixou de ser apenas uma etapa metodológica obrigatória e passou a assumir um papel central na validação de resultados, na formulação de conclusões e na tomada de decisão estratégica.
No entanto, aplicar corretamente técnicas estatísticas exige mais do que conhecimento técnico isolado. É necessário compreender o desenho do estudo, os pressupostos dos modelos utilizados e, sobretudo, interpretar os resultados de forma crítica e fundamentada.
Neste contexto, a consultoria em análise estatística surge como um apoio especializado que garante rigor metodológico, clareza interpretativa e adequação das técnicas às características específicas de cada projeto, seja ele académico ou empresarial.
1. O Papel da Estatística na Investigação Científica
A estatística é um instrumento essencial na investigação científica, permitindo transformar dados em evidência empírica. Através de métodos estruturados de recolha, organização e análise de dados, é possível sustentar conclusões com base quantitativa sólida.
No contexto académico, a estatística descritiva permite caracterizar amostras por meio de médias, desvios-padrão e frequências, enquanto a estatística inferencial possibilita generalizações para a população através de testes de hipóteses e intervalos de confiança.
2. Testes de Hipóteses e Estatística Inferencial
O teste de hipóteses constitui um dos pilares da análise estatística. A formulação da hipótese nula (H0) e da hipótese alternativa (H1) permite avaliar evidência estatística com base em níveis de significância previamente definidos.
Entre os testes mais utilizados encontram-se o teste t, ANOVA, qui-quadrado e modelos de regressão. A escolha adequada do teste depende do desenho do estudo, tipo de variáveis e pressupostos estatísticos.
3. Análise Estatística em Contexto Empresarial
No ambiente empresarial, a análise estatística apoia decisões estratégicas através de estudos de mercado, análise de desempenho, avaliação de satisfação do cliente e construção de modelos preditivos.
A utilização de ferramentas como SPSS, JASP, Jamovi e AMOS permite aplicar análises univariadas, multivariadas e modelos de equações estruturais, assegurando rigor metodológico e clareza interpretativa.
4. Importância da Interpretação dos Resultados
A interpretação correta dos resultados estatísticos é determinante para a credibilidade científica e eficácia organizacional. Mais do que aplicar técnicas, é fundamental compreender pressupostos, limitações e implicações práticas dos resultados obtidos.
Conclusão
A consultoria em análise estatística constitui um apoio especializado para investigadores e empresas que procuram decisões fundamentadas. O rigor metodológico, aliado à interpretação técnica adequada, permite transformar dados em conhecimento estratégico.
Tipos e Métodos de Amostragem
Autor: Flávia Negrini
As amostragens probabilísticas
A amostragem será classificada como probabilística caso cada elemento na população tenha a mesma probabilidade de pertencer a mesma amostra e esta seja diferente de zero, sendo as técnicas de amostragens probabilísticas mais frequentes a saber: amostragem aleatória simples; a amostragem sistemática, amostragem aleatória estratificada e a amostragem em Cachos.
Amostragem Aleatória Simples
A amostragem aleatória simples é uma técnica de acordo com a qual cada um dos indivíduos da população alvo tem a mesma probabilidade de ser selecionado para integrar uma amostra, sendo utilizado no caso de uma população ser homogênea. Para tanto, deve-se proceder à numeração de todos os sujeitos da população e, por meio de um sorteio ou ajuda de uma tabela formada por números aleatórios, conseguir aqueles que formarão a amostra almejada. Assim, uma amostra aleatória simples pode ser formada conforme duas técnicas: amostra com reposição ou amostra sem reposição, sendo que na amostragem com reposição, a unidade escolhida volta para a população enquanto que na amostragem realizada sem reposição, a unidade escolhida não volta para a população. Assim sendo, é válido notar que, de modo geral, as amostragens são realizadas sem reposição e os cálculos de estatística nos dois tipos são iguais.
Amostragem Sistemática
A amostragem sistemática também poderá ser utilizada apenas se existir uma relação ordenada de integrantes da população, como, por exemplo por ordem alfabética ou lista telefónica. Tal técnica está baseada na retirada de K integrantes dessa lista sendo o primeiro deles retirado ao acaso, sendo que equivale à razão entre a extensão da população e da amostra. Assim sendo, a amostragem sistemática é a mais adequada pois é possível a definição de um até conseguir a amostra do tamanho almejado.
Amostragem Aleatória Estratificada
A amostragem estratificada será utilizada quando a população tiver características precisas como, por exemplo, idade e sexo, que possibilitem a formação de subconjuntos homogêneos ou os denominados estratos, uma vez que, nestas situações, as amostras selecionadas por amostragem simples tem menor representatividade, sendo em seguida retirado de modo aleatório uma amostra relativa a cada um dos estratos. Assim, tal forma de amostragem é uma das mais aplicadas, já que a maioria das populações possuem estratos bem definidos, como, por exemplo, os de homens e os de mulheres, sendo que entre suas vantagens estão as seguintes:
- Os dados são em geral mais homogéneos dentro de cada subconjunto do que na população total
- O custo para recolha e análise dos dados é quase sempre mais baixo do que na aleatória simples;
- É possível conseguir estimativas separadas dos parâmetros da população para cada estrato sem escolher outra amostra, ou seja, sem qualquer custo extra.
Amostragem em Cachos ou conglomerados
A amostragem em cachos está baseada na retirada de modo aleatório dos elementos por cachos e não unidades, sendo útil quando os elementos da população devem ser considerados como grupos ou quando não é viável obter uma relação de todos os sujeitos da população-alvo. Assim, é válido saber que em todo agrupamento (cachos ou estratos), a amostra só é tida como probabilística se os grupos forem selecionados ao acaso antes da separação aleatória dos indivíduos nos estratos. O número de integrantes em cada conglomerado deve ser pequeno em comparação a extensão da população, mas devem conter grandes quantidades de estratos. Tal amostragem será indicada quando não se tem um sistema de referência ordenando todos os integrantes da população, ou tal elaboração seja muito custosa, sendo que o custo do alcance de dados aumenta com o crescimento da distância entre os mesmos.
As Amostragens Não Probabilísticas
É uma estratégia de seleção de acordo com a qual cada integrante da população não tem a mesma probabilidade de ser selecionado para constituir a amostra, sendo a extensão da amostra extremamente importante uma vez que quanto maior for, menor será a probabilidade de que casos incomuns possam influenciar a totalidade de maneira significativa. Por isso, as amostras provenientes desta modalidade de amostragem devam ter sempre um número acima daquele que representaria a totalidade caso fosse usada uma amostragem da modalidade probabilística. Assim sendo, as técnicas de amostragens não-probabilísticas são: amostragem acidental ou de conveniência (por substituição da aleatória simples); amostragem por cotas (por substituição da amostragem estratificada ou por cachos); amostragem de seleção racional ou tipicidade (por substituição da estratificada); amostragem por Redes ou Bola de Neve (por substituição da sistemática).
Amostragem Acidental ou de Conveniência
É constituída por indivíduos que possam ser contactados de modo fácil, que estão numa localidade específica e momento preciso, tendo a vantagem de ser de simples organização e custo baixo, entretanto, tal modalidade de amostra gera enviesamentos, pois nada aponta que os primeiros 30 sujeitos sejam representativos da população-alvo. Assim sendo, são aplicadas a pesquisas que não têm como fim generalizar os resultados sendo muitas vezes usadas em hospitais. Dessa forma, é relevante a visão crítica do investigador para evitar vieses, por exemplo, não escolher sempre sujeitos com idades próximas, empregando critérios específicos de inclusão e exclusão.
Amostragem por Quotas
Igual à amostragem aleatória estratificada, uma vez que é formada por uma quantidade pré-determinada de sujeitos em cada uma das diversas categorias da população. Tal amostragem será diferente da estratificada somente pelo facto dos indivíduos não serem selecionados de modo aleatório dentro de cada cota ou grupo.
Amostragem por Seleção Racional, Julgamento ou por Tipicidade
Tem como pilar a avaliação do pesquisador ou especialista para formar uma amostra de indivíduos em função do seu carácter típico ou atípico cujos integrantes tenham ótimas possibilidades de fornecerem os dados que o estudo demanda, como, por exemplo, a investigação de casos que fogem à regra como uma doença muito rara.
Amostragem por Redes ou Bola de Neve
Este método está baseado na seleção de indivíduos que não seriam fáceis de serem encontrados de outro modo, tendo-se em mente as redes sociais, ciclo de amigos e conhecimentos, por exemplo, caso o pesquisador ache pessoas que satisfaçam os critérios estabelecidos e solicita que recomendem outros indivíduos que possuam características semelhantes.
Referências Bibliográficas
Pocinho, M. (2009) Teoria e exercícios passo-a-passo: Amostra e tipos de amostragem. Publicado por Research Gate. https://www.researchgate.net/publication/268150358
Validação, Tradução e Adaptação de Instrumentos Psicológicos

Autor: Flávia Negrini
A adaptação de instrumentos psicológicos é difícil e exige alto rigor na metodologia utilizada. Assim, a adaptação de tais instrumentos não é fácil e demanda planeamento e exigências no que toca à preservação do conteúdo, psicometria e validação para a amostra a quem se direciona (Cassepp-Borges, Balbinotti, & Teodoro, 2010)
Por isso, será devida a comprovação das evidências que provam a correspondência de sentidos dos pontos estudados assim como as medidas psicométricas da versão reformulada do instrumento em questão (International Test Commission [ITC], 2010
Além disso, esta adaptação inclui um ajustamento à cultura, ou seja, a preparação do instrumento para utilização em contextos novos (Beaton, Bombardier, Guillemin, & Ferraz, 2000; Hambleton, 2005; Sireci, Yang, Harter, & Ehrlich, 2006).
A International Test Commission (ITC) trabalha desde 1992 para sugerir orientações para a traduzir e adaptar instrumentos psicológicos entre sociedades com culturas distintas (ITC, 2010).
Assim, traduzir é a primeira ação para tal adaptação, uma vez que ao adaptarmos um instrumento, teremos que ter em conta uma série de aspetos tais como aqueles da cultura, idioma, língua e contextos próprios à tradução do mesmo (Hambleton, 2005). Após feita essa adaptação, é viável a realização de pesquisas entre populações distintas, fazendo analogias entre traços de pessoas de culturas distintas (Gjersing, Caplehorn, & Clausen, 2010; Hambleton, 2005).
O processo de adaptação de um instrumento que já existe para criar um outro instrumento, voltado para a população-alvo, é vantajoso por várias razões uma vez que ao fazer tal ajuste do instrumento, o investigador pode comparar informações de amostras distintas, advindas de mais de um contexto, o que possibilita aumento da equivalência na hora de avaliar resultados, pois se refere a uma igual medida, que realiza uma avaliação partindo de uma mesma visão a nível teórico e metodológico, o que viabilizará também um maior potencial para fazer generalizações e estudar aquilo que é diferente em outras populações (Hambleton, 2005; Vivas, 1999).
Assim, de modo amplo, a literatura indica que para adaptar um instrumento deve haver cinco etapas importantes: (1) traduzir o instrumento do idioma original para o idioma da minha população-alvo, (2) realizar um resumo das versões já traduzidas, (3) analisar a versão resumida por meio de juízes especializados, (4) traduzir de forma reversa para o idioma de original, e (5) estudo-piloto (Hambleton, 2005; Sireci et al., 2006).
Entretanto, percebe-se que, nessas etapas, não constam demais aspetos significativos para a adaptação do novo instrumento elaborado, como, por exemplo, a avaliar de forma conceitual alguns pontos pela própria população-alvo e discutir com quem fez o instrumento original acerca de adaptações e alterações sugeridas para o modelo reformulado do instrumento.
O primeiro ponto significativo a se ter em conta, na adaptação de um instrumento, é a sua tradução para o idioma da população-alvo, ou seja, o idioma no qual o novo instrumento será aplicado, sendo este passo algo difícil, pois, demanda vários cuidados para que o instrumento obtido seja bem adaptado para o contexto de destino e ao mesmo tempo esteja em congruência com aquela versão anterior (Tanzer, 2005).
Dessa forma, antigamente era consenso que somente um tradutor seria o bastante para fazer esta tradução, mas atualmente os estudiosos aconselham que a tradução seja feita por dois tradutores bilíngues, o que reduzirá o risco de outras interpretações com base na linguagem, psicológicas, culturais e de perceção da teoria e da aplicação prática do instrumento (Cassepp-Borges et al., 2010)
A segunda etapa equivale a comparação entre as distintas traduções e avaliação das discrepâncias a nível semântico, idiomático, conceitual, linguístico e contextual, com o propósito de alcance de apenas uma versão, sendo nesse momento possível que surjam dois complicadores: (1) traduções difíceis que tornem mais difícil o entendimento da população-alvo ou (2) traduções muito simplificadas que reduzem o conteúdo de um dado ponto do estudo.
Assim, opções inadequadas serão identificadas e solucionadas por meio de trocas entre os juízes especialistas e investigadores incumbidos de avaliar o instrumento em causa.
Depois do resumo da nova versão, o investigador ter a ajuda de um comitê de especialistas em avaliação a nível psicológico ou que sejam especializados no construto que o instrumento procura avaliar, o qual fará a avaliação de fatores ainda não considerados, como a estrutura e amplitude do novo instrumento.
Nesse momento, os especialistas farão uma avaliação, por exemplo, se algumas expressões empregadas poderão ser ampliadas para outros contextos e amostras populacionais, como as de diversas zonas de uma mesma nação e se estas são apropriadas para a população-alvo.
A tradução reversa é compreendida como uma checagem do controlo de qualidade incremental. Assim, tal etapa irá acontecer depois de todos os ajustes de significados e de idioma, pois, nesse momento o instrumento precisará estar em condições de ser submetido a avaliação por aquele autor que criou originalmente o instrumento (Sireci et al., 2006)..
Dessa forma, a tradução reversa diz respeito a tradução da versão já resumida e revista para o idioma original, tendo como meta avaliar em que nível de precisão a versão nova reflete o conteúdo dos pontos propostos pela versão de origem.
Entretanto, antes de confirmarmos que o novo instrumento está válido para ser aplicado, deve ser conduzido um estudo-piloto, que diz respeito a uma aplicação em momento prévio do instrumento em uma amostra reduzida que esteja de acordo com traços da amostra-alvo (Gudmundsson, 2009).
Assim, depois das alterações propostas no primeiro estudo-piloto, deverá ser feito um segundo estudo-piloto ou a quantidade que for necessária para avaliação precisa do instrumento, antes que este seja aplicado.
No campo da Psicologia têm crescido o número de estudos transculturais, o que, têm demandado maior rigor e cuidado no que toca ao aperfeiçoamento da qualidade e adequação de medições ajustadas e válidas para utilização em diversos cenários (ITC, 2010).
Embora seja sabido que a relevância da adaptação desses instrumentos para culturas diferentes, investigadores têm ressaltado que a maior parte dos estudos nessa área têm sido invalidados devido ao facto de serem consideradas inadequadas a tradução e adaptação dos instrumentos em questão. (Hambleton, 2005).
Tais adaptações são baseadas na tradução de itens para o idioma da população-alvo, sendo que muitas vezes são feitas pelos investigadores da pesquisa que realizam a tradução reversa, na qual verifica-se somente o nível de equidade de sentidos entre um modelo adaptado e aquele original (Cassepp-Borges et al., 2010; Hambleton, 2005; Reichenheim & Moraes, 2003).
Nos estudos da área da psicologia é comum a pesquisa sobre um constructo psicológico por meio do uso de certos instrumentos, como inventários de autorrelato, inquéritos e escalas, especialmente na clínica ou no setor da saúde.
Por isso, se num determinado contexto não existe um instrumento de medição para um certo constructo, este será procurado em países onde já foram feitos testes para validação de versões do instrumento já aplicadas a estudos da mesma natureza e âmbito (Cassep-Borges; Balbinotti; Teodoro, 2010; Duarte; Bordin, 2000).
Não existe um consenso acerca do modo de adaptação de um instrumento para sua utilização no contexto de outra cultura, pois, este procedimento vai variar de acordo com o instrumento e contexto onde se aplica e amostra de destino. Entretanto, existe um consenso de que tal adaptação inclui mais do que a simples tradução, que não assegura a validação do construto e a confiabilidade daquilo que se pretende medir.
De acordo com o International Test Commission (ITC, 2005) as orientações para adaptar testes e demais instrumentos psicológicos devem ter como base a comparação com códigos que já existem no país, procurando fazer com que estes sejam devidamente reconhecidos e tidos como consistentes em outros países. Assim, a tradução e adaptação deve abranger os contextos da língua e cultura da amostra de destino, sendo conservado o mesmo nível de qualidade do instrumento de origem.
Tais orientações da Comissão de Testes Internacional englobam: (a) a utilização da língua devendo ser adequada para todas as amostras populacionais no que toca á diversidade de culturas e línguas de destino; (b) a escolha de uma técnica, forma dos itens e meios de ação, que precisa ser conhecida a todas as amostras-alvo; (c) o conteúdo dos itens e materiais precisam ser já conhecidos a todas as amostras-alvo; e (d) deve ser assegurado que o projeto de recolha de dados possibilita a utilização das técnicas estatísticas pertinentes para estabelecimento da equivalência de itens entre os diversos modelos linguísticos da(s) testagem (s) ou instrumento(s) (ITC, 2005).
A validade de construto se refere ao potencial do instrumento em refletir realmente o tema que procura estudar (Kazdin, 2010).
Assim, uma das opções é usar outro instrumento que possa proceder a avaliação do mesmo construto e fazer a medição da correlação entre eles, sendo que os resultados alcançados através de outro teste validado vão predizer igual desempenho que o anterior e vão servir de base para estabelecer a validação do novo instrumento validado (Pasquali, 2009).
Dessa forma, ambos os instrumentos precisam mostrar evidências de validação ao convergirem ou mostrarem importantes e altos indicadores que apontam correlações. (Shaughnessy; Zechmeister; Zechmeister, 2012).
A confiabilidade é capacidade de produzir resultados consistentes no tempo e espaço, ou por meio de observadores distintos, apontando aspetos acerca da coerência, precisão, estabilidade, equivalência e homogeneidade. (Terwee et al, 2007).
Então, a escolha dos testes estatísticos utilizados para avaliação da confiabilidade varia conforme aquilo que se quer medir (Keszei, Novak e Streiner, 2010).
Já no que toca à validade, existem três tipos mais importantes, validade de conteúdo, validade de critério e validade de construto, sendo que no que toca a este último, é difícil que seja obtida sua validação através de uma única pesquisa, sendo realizadas inúmeras pesquisas acerca da teoria do constructo que se deseja medir (Polit & Beck, 2011; Martins, 2006), pois, quanto maiores as evidências, maior validação terão as conclusões acerca dos resultados obtidos (Kimberlin & Winterstein, 2008).
Assim, os investigadores fizeram uma subdivisão da validade de um constructo em três modalidades: o teste de hipóteses, a validade estrutural e a validade transcultural (Mokkink et al, 2010; Polit, 2015).
Bibliografia
Beaton, D. E., Bombardier, C., Guillemin, F., & Ferraz, M. B. (2000). Guidelines for the process of crosscultural adaptation of self-report measures. Spine, 25(24), 3186-3191.
Cassepp-Borges, V., Balbinotti, M. A. A., & Teodoro, M. L. M. (2010). Tradução e validação de conteúdo: Uma proposta para a adaptação de instrumentos. In L. Pasquali, Instrumentação psicológica: Fundamentos e práticas (pp. 506-520). Porto Alegre: Artmed.
Duarte, C; Bordin, I.A.S. Instrumentos de Avaliação. Rev. Bras. Psiquiatr, v. 22, n. Supl II, p. 55–58, 2000.
Gjersing, L., Caplehorn, J. R. M., & Clausen, T. (2010). Cross-cultural adaptation of research instruments: Language, setting, time and statistical considerations. BMC Medical Research Methodology, 10, 13. doi:10.1186/1471-2288-10-13
Gudmundsson, E. (2009). Guidelines for translating and adapting psychological instruments. Nordic Psychology, 61(2), 29-45. doi:10.1027/1901-2276.61.2.29
Hambleton, R. K. (2005). Issues, designs, and technical guidelines for adapting tests into multiple languages and cultures. In R. K. Hambleton, P. F. Merenda, & C. D. Spielberger (Eds.), Adapting educational and psychological tests for cross-cultural assessment (pp. 3-38). Mahwah, NJ: Lawrence Erlbaum.
Haughnessy, J. J; Zechmeister, E.B; Zechmeister, J.S. Metodologia de Pesquisa em Psicologia. Porto Alegre: AMGH Editora, 2012.
ITC. ITC Guidelines for Translating and Adaptating Tests. [s.l: s.n.]. Disponível em: <http://www.intestcom.org/upload/sitefiles/40.pdf>.
International Test Commission. (2010). International Test Commission guidelines for translating and adapting tests. Recuperado em 24 julho 2012, de http://www.intestcom.org/upload/sitefi les/40.pdf
Kazdin, A. E. Research Design in Clinical Psychology. 4. ed. New York: Allyn&Bacon, 2010.
Keszei AP, Novak M, Streiner DL. Introduction to health measurement scales. J Psychosom Res. 2010 Apr;68(4):319-23.
Kimberlin CL, Winterstein AG. Validity and reliability of measurement instruments used in research. Am J Health Syst Pharm. 2008 Dec;65(23):2276-84.
Mokkink LB, Prinsen CAC, Bouter LM, Vet HCW, Terwee CB. The COnsensus-based Standards for the selection of health Measurement Instruments (COSMIN) and how to select an outcome measurement instrument. Braz J Phys Ther. 2016 Mar-Apr;20(2):105-13.
Pasquali, L. Psicometria. Rev Esc EnfermUSP, v. 43, p. 992–999, 2009.
Reichenheim, M. E., & Moraes, C. L. (2003). Adaptação transcultural do instrumento Parent-Child Confl ict Tactics Scale (CTSPC) utilizado para identificar a violência contra a criança. Cadernos de Saúde Pública, 19(6), 1701-1712. doi:10.1590/S0102-311X2003000600014
Sireci, S. G., Yang, Y., Harter, J., & Ehrlich, E. J. (2006). Evaluating guidelines for test adaptations: A methodological analysis of translation quality. Journal of Cross-Cultural Psychology, 37(5), 557-567. doi:10.1177/0022022106290478
Tanzer, N. K. (2005). Developing tests for use in multiple languages and cultures: A plea for simultaneous development. In R. K. Hambleton, P. F. Merenda, & C. D. Spielberger (Eds.), Adapting educational and psychological tests for cross-cultural assessment (pp.235-264). Mahwah, NJ: Lawrence Erlbaum.
Terwee CB, Schellingerhout JM, Verhagen AP, Koes BW, Vet HC. Methodological quality of studies on the measurement properties of neck pain and disability questionnaires: a systematic review. J Manipulative Physiol Ther. 2011 May;34(4):261-72.
Vivas, E. (1999). Estudios transculturales: Una perspectiva desde los trastornos alimentarios. In S. M. Wechsler & R. S. L. Guzzo (Orgs.), Avaliação psicológica: Perspectiva internacional (2a ed., pp. 463-481). São Paulo: Casa do Psicólogo.
Teoria de Amostragem e Cálculo Amostral
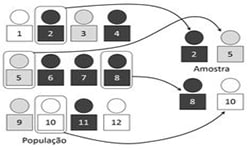
Autor: Flávia Negrini
A Teoria da Amostragem diz respeito à estratégia a ser utilizada para seleção de uma amostra, além de fornecer mais informações acerca do modo de ação no que toca ao uso de uma metodologia de amostragem para uma investigação ou estudo
Dessa forma, assim que o pesquisador estabeleça a população potencial para sua investigação, ele deve fixar critérios de escolha dos seus constituintes, que podem ser para incluir ou excluir pessoas que integrarão o estudo, sendo que uma amostra é considerada representativa caso as suas características se pareçam o mais possível às da população-alvo.
É assim importante que a amostra ilustre não apenas as variáveis sob investigação, mas também outros fatores que possam exercer algum impacto sobre as variáveis da pesquisa, como a idade, o sexo, a escolaridade e o rendimento.
Assim, o potencial de representatividade de uma amostra, é avaliado através da comparação entre as médias da amostra com as da população-alvo, sendo o conceito de amostra definido como o conjunto de elementos extraídos de uma população, que de modo suficiente, representem essa população. Assim sendo, após a definição da amostra, estaremos prontos para efetuar a análise dos resultados como se investigássemos a população na sua totalidade.
A amostra será sempre finita, entretanto, quanto maior for esta, mais valiosa é a pesquisa. No entanto, como sempre há dúvidas de que todas as características da população estão representadas numa amostra, já que estas não costumam ser conhecidas, partindo-se do princípio de que um certo grau de erro sempre estará presente.
Assim, os resultados de investigações por amostragem estão sempre expostos a uma determinado grau de incerteza, não apenas porque se estudou somente uma parte da população, mas também devido a falhas de mensuração, sendo que tal grau de incerteza pode ser diminuído com o crescimento do tamanho da amostra e através do uso de ferramentas mais eficazes de mensuração.
A teoria da amostragem tem em conta duas dimensões:
1ª) Dimensionamento da Amostra e
2ª) Composição da Amostra, sendo inúmeros os meios de determinação da extensão de uma amostra. No entanto, será preciso voltar a atenção para os seguintes pontos:
- Análise do inquérito ou roteiro da entrevista e selecionar uma ou mais variáveis que avalie serem mais significativas para o estudo.
- Conferir o nível de mensuração da variável: nominal, ordinal ou intervalar;
- Ter em conta a extensão da população: infinita ou finita
- O tamanho da amostra é determinado em função do grau de mensuração da variável selecionada.
- São inúmeras as fórmulas que possibilitam o cálculo da extensão de uma amostra e sua seleção dependerá do que é estudado ou dos parâmetros à disposição.
A seguir são apresentadas algumas fórmulas para cálculos amostrais:
Variável intervalar e população finita
Quando a variável é de nível intervalar e a população é considerada finita, determina-se o tamanho da amostra pela fórmula:
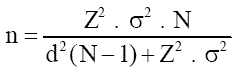
onde:
Z = abscissa da normal padrão
N = tamanho da população
d = erro amostral
Variável qualitativa (nominal ou ordinal) e população finita
Quando a variável for nominal ou ordinal e a população for considerada finita, determina-se a extensão da amostra através da fórmula:
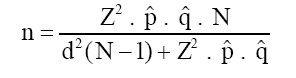
onde:
Z = abscissa da normal padrão
N = tamanho da população
p = estimativa da proporção.
𝑞 = 1- p
d = erro amostral
Assim, as fórmulas citadas acima são básicas para toda modalidade de composição da amostra. No entanto, existem fórmulas específicas de acordo com o critério relativo à composição da amostra. Caso não existam condições de previsão do possível valor para 𝑝, será admitida 𝑝 =0,50 pois, assim, teremos a maior extensão da amostra, considerando constantes os outros elementos.
Determinação da Margem de Erro da Amostra
A Margem de erro de uma amostra que representará de modo aproximado uma população é explicada da seguinte forma: Pot exemplo caso uma investigação possua uma margem de erro de 3% e um certa doença teve 20% de prevalência na amostra formada, podemos falar que, naquele momento, na população em questão, ela terá uma prevalência entre 17% e 23% (20% menos 3% e 20% mais 3%). O nível de confiança é definido como um parâmetro utilizado pelas investigações, que é frequentemente de 95%, que significam que caso realizemos uma nova pesquisa, com uma amostra de igual extensão, nas mesmas datas e lugares e com a mesma ferramenta para coleta de dados, existirá uma probabilidade de 95% de que os resultados sejam iguais e uma probabilidade de 5% de que tudo seja diferente.«
Fórmula para conhecer a margem de erro padrão
sp =raiz quadrada de (p. q) /n
De acordo com Agranonik e Hirokata (2009), é notório que a extensão da amostra para estimar uma proporção cresce, quando o nível de confiança do intervalo aumenta ou quando é reduzida a margem de erro. Por isso, caso o objetivo seja fazer a comparação entre proporções, a extensão da amostra aumentará, quando for diminuído o nível de significância, quando é aumentada a eficácia do teste, ou quando for reduzida a menor diferença relevante que almeja-se identificar entre as proporções.
Assim sendo, caso seja identificado um efeito de significância, igual ou superior ao estabelecido no cálculo, ele será percebido como importante do ponto de vista estatístico. Já ao ser estimada uma proporção por meio de intervalo de confiança, para reduzirmos a extensão da amostra, será preciso reduzir o nível de confiança, ou fazer crescer a margem de erro, sendo que a prevalência aplicada deve ser a encontrada em pesquisas anteriores conduzidas em uma amostra advinda de uma população parecida e de forma aproximada ao da investigação atual.
Entretanto, é facto conhecido que, em algumas situações, há limitações à extensão da amostra, por causa de recursos financeiros ou do tempo de recolha. No entanto, o tamanho da amostra deve ser o reflexo do verdadeiro objetivo da investigação, no sentido da extensão de efeito ou precisão do cálculo da estimativa
Exemplo de cálculo de tamanho de amostra para uma proporção
Almeja-se estimar a prevalência do tabagismo em jovens do Porto, com nível de confiança de 95% e margem de erro de 0,05. Não havendo estudos prévios, é possível utilizar a proporção de 50% na fórmula 2, sendo obtido o seguinte tamanho de amostra:
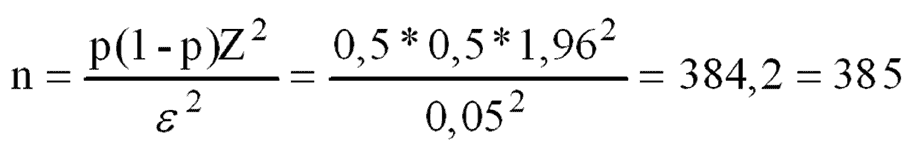
p = 0,50
1- p = 1- 0,50 = 0,50
Nível de confiança: 95% Z = 1,96
É relevante notar que o cálculo da extensão da amostra ilustra o número mínimo necessário de indivíduos que devem ser entrevistados para alcançar um determinado objetivo. Assim, caso o valor auferido não seja um número inteiro, ele deverá ser arredondado para mais.
Para determinação da extensão da amostra a fim de comparar 2 proporções, é essencial que o investigador defina:
1- Qual a hipótese nula e decida se a hipótese alternativa é uni ou bidirecional;
2- A estimativa da magnitude de efeito e a variabilidade em termos de p1 (proporção de sujeitos em um dos grupos) e p2 (proporção de sujeitos com o desfecho no outro grupo);
3- O nível de significância (α) e o poder (1 – β).
A extensão da amostra para comparar 2 proporções (p1 e p2), para grupos de igual tamanho, pode ser estimada pelo uso da fórmula que segue onde:
n: é o número de sujeitos necessários em cada um dos grupos
p1: é a proporção esperada para o grupo 1,
p2: é a proporção esperada para o grupo 2
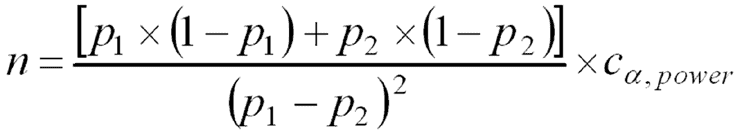
Bibliografia
Agranonik, M & Hirokata, V. Cálculo de tamanho de amostra: proporções. Revista HCPA. 2011; 31 (3): 382-388. Seção de Bioestatística.
Pocinho, M. (2009) Teoria e exercícios passo-a-passo: Amostra e tipos de amostragem. Publicado por Research Gate. https://www.researchgate.net/publication/268150358
Explicações de análise estatística de dados

Encontra-se com dificuldades na análise estatística de algum trabalho ou projeto ou simplesmente necessita de apoio para a realização de um determinado exame?
Com o nosso serviço de explicações em análise estatística de dados poderá colmatar todas as suas dúvidas e obter os melhores resultados possíveis e sucesso profissional e académico.
Através de um sistema de explicações, que poderá ser presencial ou online (via Skype), poderá colocar todas as suas dúvidas ou mesmo ter aulas/explicações mediante marcação. Neste serviço de análise estatística abordamos várias questões como:
- Questões metodológicas – definição de objetivos, hipóteses e questões de investigação; design do estudo a desenvolver; procedimentos para a recolha e análise de dados; principais aspetos a considerar para uma correta análise e discussão de resultados;
- Suporte teórico relativo aos vários testes estatísticos a utilizar de acordo com as questões apresentadas;
- Realização de exercícios práticos para apoio ao estudo para exames ou frequências
- Explicação sobre o cálculo de resultados com recurso ao SPSS e AMOS
Discussão dos resultados obtidos no SPSS

Após a obtenção de resultados e análise estatística dos mesmos, através de testes existentes no SPSS, realiza-se de forma clara e objetiva a ponte entre a teoria previamente construída (pressupostos teóricos, estudos de investigação) e os resultados obtidos, com a finalidade de comprovar ou esclarecer de forma concisa e coerente as questões e objetivos levantados numa fase metodológica inicial.
A discussão dos resultados obtidos pelo SPSS permite assim a retirada de conclusões relativas a uma determinada amostra ou população em estudo, servindo como referência à realização de novos estudos de investigação ou desenvolvimento e implementação de programas de intervenção em determinadas áreas.
Análise dos resultados obtidos em SPSS
Os dados obtidos são analisados pelo SPSS de diversas formas com o objetivo de dar resposta às hipóteses, questões de investigação ou objetivos estipulados para o seu trabalho académico.
Os testes utilizados pelo SPSS permitem realizar diversas análises descritivas (Ex: Medidas de Tendência Central, Dispersão e Distribuição) para uma pequena descrição dos resultados obtidos, correlação entre variáveis de forma a verificar se existe influência significativa de uma variável noutra (Ex: Correlação de Pearson e Correlação de Spearman) e também comparações de frequências e médias entre grupos, com recurso a Testes Paramétricos (Ex: Test t e Teste Anova) e Não paramétricos (Ex:Teste Mann-Whitney e Teste Kruskall-Wallis).
O SPSS permite também a realização de análises mais complexas e multi variadas tais como:
- Regressões lineares: Com o SPSS é possível estabelecer previsões relativas a relação entre variáveis, assim como a escolha de modelos explicativos mais significativos de mudança de uma variável relativamente a determinado aspecto ou condição.
- Análise Factorial e de Clusters: O SPSS permite também formular novas variáveis explicativas de um determinado aspeto ou condição a partir de um conjunto mais numeroso de variáveis.
A utilização deste tipo de análises em SPSS é muito útil para a formulação de conjuntos ou aglomerados de dados com características em comum (Análise de Clusters) e também para a criação de sub-escalas relativas a questionários ou instrumentos de avaliação (Análise Factorial).
Realização de Bases de dados em SPSS

Através do SPSS é possível criar bases de dados que permitem analisar de forma rápida clara e objetiva os resultados relativos a um determinado aspeto ou questão a investigar, procurando promover e facilitar ao máximo o processo de análise estatística de dados.
O serviço de criação de base de dados consiste na elaboração de uma base de dados, através da criação em SPSS de variáveis de diversos tipos e inserção de dados obtidas de diversas fontes (Ex: Questionários, Entrevistas, Registos, outras bases de dados). Para além disso é possível facilitar a análise estatística dos dados, através de alterações na base de dados tais como:
- Transformação de variáveis, através da criação de novas variáveis a partir de variáveis já existentes (processo de categorização) e por computação (mediante cálculos estatísticos como média, soma, entre outros)
- Criação de novas variáveis que se definem como agrupamentos de outras variáveis (ex: processo de criação de factores a partir de variáveis latentes)
- Análise de valores perdidos (missing values) e respectiva substituição (métodos pairwise, listwise e replace with mean)