Análise Estatística de Dados
Para investigação e estudos de mercado
Análise Categórica e Principais Testes Estatísticos
Autor: Mário Rocha
Introdução
A análise categórica envolve métodos estatísticos utilizados para estudar variáveis qualitativas ou categóricas, como género, estado civil, presença/ausência de doença ou categorias de resposta em questionários. Este tipo de análise é fundamental em áreas como saúde, psicologia, marketing, educação e ciências sociais, permitindo identificar associações, padrões e probabilidades entre categorias (Hazra & Gogtay, 2016).
As variáveis categóricas podem ser nominais (sem ordem) ou ordinais (com ordem lógica), sendo que os dados são normalmente organizados em tabelas de contingência e analisados através de testes estatísticos específicos (Hazra & Gogtay, 2016).
São diversos os testes estatisticos que trabalham com dados categóricos como: 1) Teste Qui-Quadrado e respectivas alternativas, 2) Análise de Correspondéncias Simples (Anacor) e Múltiplas (MCA), 3) Regressão Logística, 4) Decision Trees (Árvores de Decisão).
1. Teste do Qui-Quadrado (χ²)
O teste do Qui-Quadrado é um dos métodos mais utilizados na análise categórica, tendo como principal objetivo verificar se existe associação significativa entre variáveis categóricas (Hazra & Gogtay, 2016). Apresenta diferentes tipos como:
• Qui-quadrado de independência;
• Qui-quadrado de ajustamento (goodness-of-fit);
• Teste de McNemar;
• Teste exato de Fisher.
Este método estabelece a comparação entre frequências observadas com frequências esperadas e tem como principais pressupostos a necessidade dos dados serem categóricos, as observações independentes e as frequências esperadas adequadas (Hazra & Gogtay, 2016).
Em amostras pequenas, o teste exato de Fisher pode representar uma alternativa mais robusta ao Qui‑Quadrado tradicional conforme nos referiram Shan e Gerstenberger (2017). Além disso, Agresti e Caffo (2000) demonstraram melhorias importantes na estimação de intervalos de confiança associados às diferenças entre proporções.
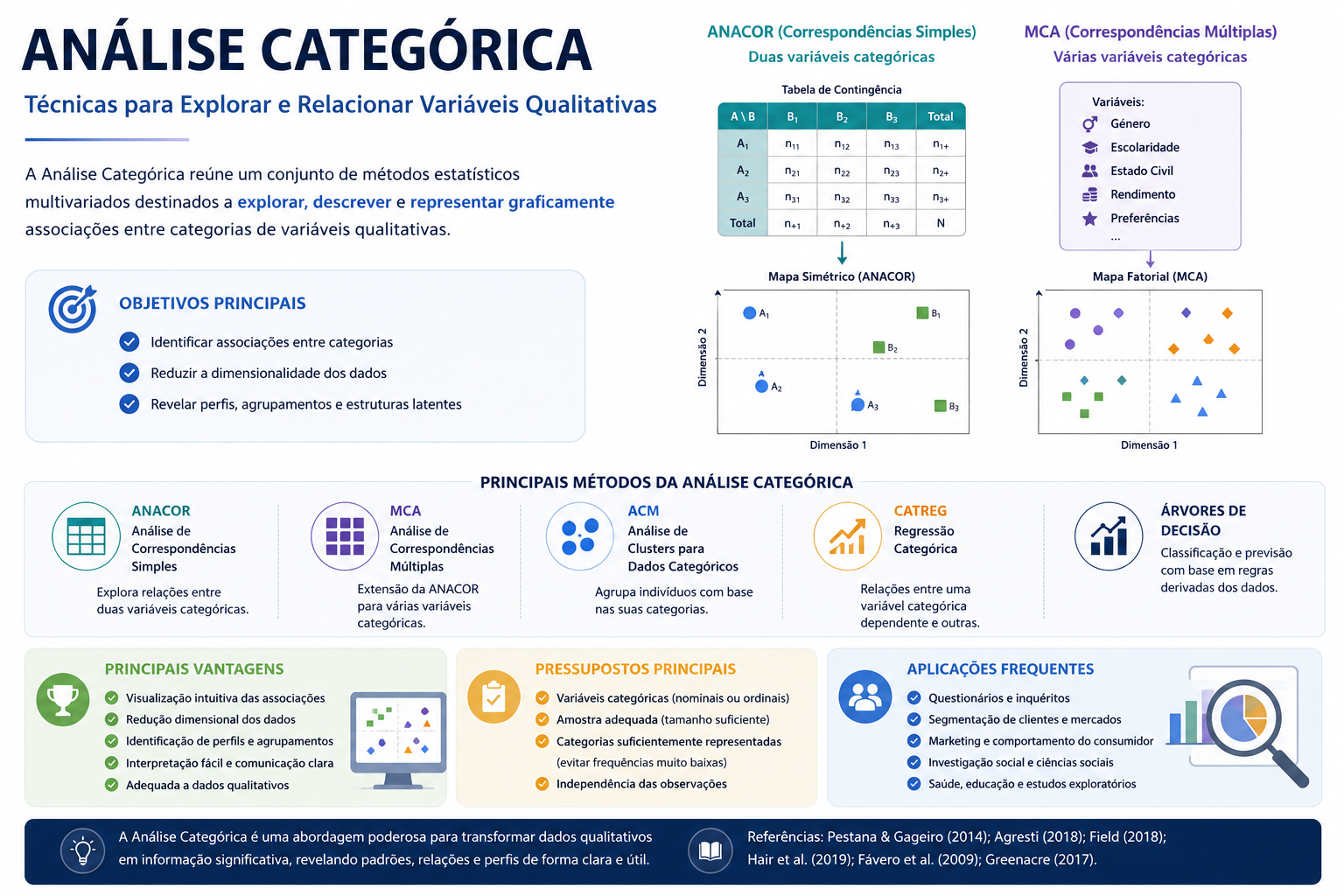
2. ANACOR e MCA
A Análise de Correspondências (ANACOR) permite representar graficamente relações entre categorias de variáveis qualitativas. Por outro lado, a Análise de Correspondências Múltiplas (MCA) é mais utilizada quando existem várias variáveis categóricas simultaneamente. Deste modo, a Análise de Correspondências Simples (ANACOR) é utilizada principalmente para explorar relações entre duas variáveis categóricas, enquanto a Análise de Correspondências Múltiplas (MCA) representa uma extensão da técnica para múltiplas variáveis categóricas simultaneamente (Pestana & Gageiro, 2014; Greenacre, 2017).
Estas técnicas são muito usadas em questionários, segmentação de clientes, marketing e investigação social. As principais vantagens incluem visualização intuitiva das associações, redução dimensional e identificação de perfis e agrupamentos. (Greenacre, 2017; Agresti, 2018).
Tem como principais pressupostos para a sua utilização a necessidade das variáveis a analisar serem categóricas, amostras adequadas e categorias suficientemente representadas. Estas abordagens são especialmente úteis em estudos exploratórios e análise de perfis multivariados (Pestana & Gageiro, 2014; Hair et al.,2019; Agresti, 2018).
3. Regressão Logística
A regressão logística é utilizada para prever probabilidades em variáveis dependentes categóricas. Ao contrário da regressão linear, trabalha com probabilidades entre 0 e 1 através da função logística (Maroco, 2021; Park, 2013; Sperandei, 2014).
Segundo Maroco (2021) os seus principais tipos são:
• Binária (Variável dependente ou de resposta dicotómica)
• Multinomial (Variável dependente ou de resposta nominal com mais de 2 categorias)
• Ordinal (Variável dependente ou de resposta ordinal)
Assim, a regressão logística permite estimar probabilidades, identificar fatores de risco, controlar variáveis de confusão e calcular Odds Ratios (OR), sendo amplamente utilizada na investigação científica e em modelos preditivos (Park, 2013).
Entre os principais pressupostos destacam-se independência das observações, ausência de multicolinearidade severa e tamanho amostral adequado (Sperandei, 2014).
4. Decision Trees (Árvores de Decisão)
As árvores de decisão são métodos de classificação e previsão amplamente utilizados em Data Mining e Machine Learning. O modelo divide sucessivamente os dados em grupos homogéneos através de regras simples (Song & Lu, 2015;Mienye & Jere, 2016).
Algoritmos conhecidos incluem CART, CHAID, C4.5 e QUEST (Kingsford & Salzberg, 2008; Mienye & Jere, 2016 ). Entre as principais vantagens destacam-se a facilidade de interpretação, a capacidade de lidar simultaneamente com variáveis categóricas e contínuas, a identificação automática de interações e a elevada capacidade preditiva (Kingsford & Salzberg, 2008; Song & Lu, 2015). Além disso, estas técnicas apresentam elevada flexibilidade e aplicabilidade em áreas como saúde, marketing, bioinformática, deteção de fraude e previsão de comportamento (Mienye & Jere, 2016).
Porém é importante salientar que estes modelos podem apresentar sensibilidade aos dados e risco de overfitting (Kingsford & Salzberg, 2008; Song & Lu, 2015)), sendo que técnicas de pruning, validação cruzada e ensemble learning são frequentemente utilizadas para melhorar a robustez e generalização dos modelos (Mienye & Jere, 2016)
Conclusão
A análise categórica reúne métodos fundamentais para investigação científica e análise de dados. O Qui‑Quadrado continua a ser uma das abordagens mais utilizadas para estudar associações entre variáveis qualitativas, enquanto técnicas como ANACOR, MCA, regressão logística e árvores de decisão oferecem abordagens mais avançadas de exploração, classificação e previsão.
A escolha do método depende dos objetivos do estudo, tipo de variável e estrutura dos dados, sendo fundamental compreender os pressupostos e limitações de cada abordagem (Hazra & Gogtay, 2016; Park, 2013).
Este artigo serve apenas como uma breve introdução à temática sendo a mesma explorada de modo mais especifico em diferentes futuros artigos.
Referências Bibliográficas
Agresti, A. (2018). Statistical Methods for the Social Sciences (5th ed.). Pearson.
Agresti, A., & Caffo, B. (2000). Simple and effective confidence intervals for proportions and differences of proportions result from adding two successes and two failures. The American Statistician, 54(4), 280–288. https://doi.org/10.1080/00031305.2000.10474560
Hazra, A., & Gogtay, N. (2016). Comparing groups – categorical variables. Indian Journal of Dermatology, 61(4), 385–392. https://doi.org/10.4103/0019-5154.185700
Kingsford, C., & Salzberg, S. L. (2008). What are decision trees? Nature Biotechnology, 26(9), 1011–1013. https://doi.org/10.1038/nbt0908-1011
Park, H.-A. (2013). An introduction to logistic regression: From basic concepts to interpretation. Journal of Korean Academy of Nursing, 43(2), 154–164. https://doi.org/10.4040/jkan.2013.43.2.154
Shan, G., & Gerstenberger, S. (2017). Fisher’s exact approach for post hoc analysis of a chi-squared test. PLOS ONE, 12(12), e0188709. https://doi.org/10.1371/journal.pone.0188709
Song, Y.Y., & Lu, Y. (2015). Decision tree methods: Applications for classification and prediction. Shanghai Archives of Psychiatry, 27(2), 130–135. https://doi.org/10.11919/j.issn.1002-0829.215044
Sperandei, S. (2014). Understanding logistic regression analysis. Biochemia Medica, 24(1), 12–18. https://doi.org/10.11613/BM.2014.003
Fávero, L. P., Belfiore, P., Silva, F. L., & Chan, B. L. (2009). Análise de Dados: Modelagem Multivariada para Tomada de Decisões. Elsevier.
Field, A. (2018). Discovering Statistics Using IBM SPSS Statistics (5th ed.). Sage.
Greenacre, M. (2017). Correspondence Analysis in Practice (3rd ed.). Chapman & Hall/CRC.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis (8th ed.). Cengage.
Maroco, J. (2021). Análise Estatística com o SPSS Statistics (8º Edição). Report Number.
Mienye, I. D., & Jere, N. (2016). A Survey of Decision Trees: Concepts, Algorithms, and Applications. IEEE Access. https://doi.org/10.1109/ACCESS.2024.3416838
Pestana, M. H., & Gageiro, J. N. (2014). Análise de Dados para Ciências Sociais: A Complementaridade do SPSS (6.ª Edição). Edições Sílabo.